
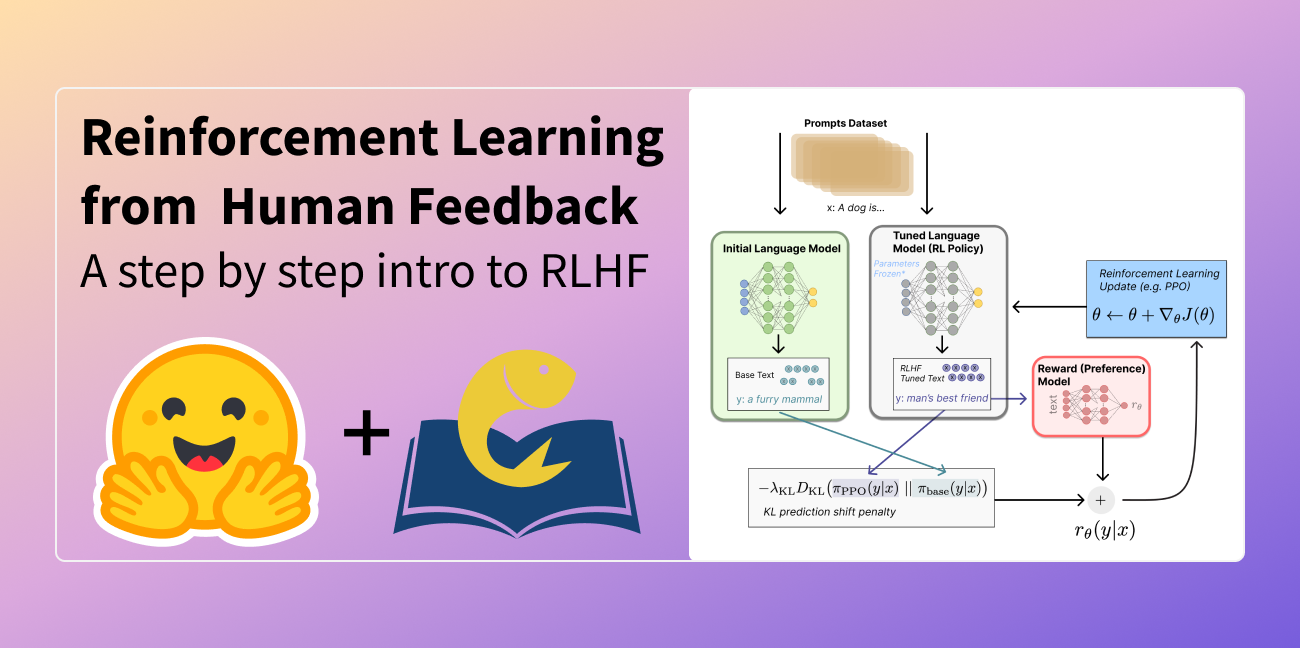
THE AI BASICS: RLHF
What is Reinforcement Learning from Human Feedback
KongsenYoung
2 min read·
What is Reinforcement Learning from Human Feedback
Reinforcement Learning (RL) is a subfield of machine learning that deals with how intelligent agents should take actions in an environment to maximize the cumulative reward. It is used to solve problems where we need to learn from an environment by trial and error, rather than by labeled input/output pairs. Instead, the focus is on finding a balance between exploration (of uncharted territory) and exploitation (of current knowledge).
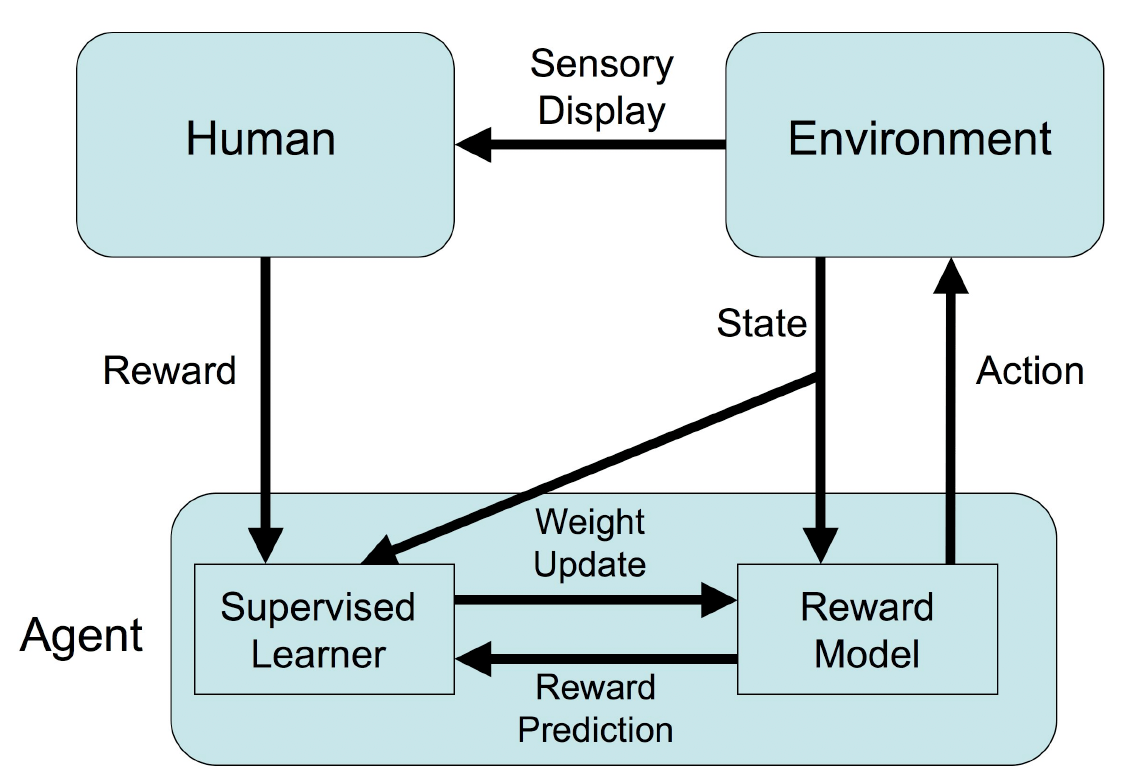
In RL, agents interact with the environment by taking actions, and the environment responds with a new state and reward. The goal of RL is to learn a policy that maximizes the expected cumulative reward. The environment is typically stated in the form of a Markov decision process (MDP), which is a mathematical framework for modeling decision-making in situations where outcomes are partly random and partly under the control of a decision maker.
RL differs from supervised learning in that it does not require labeled input/output pairs, and from unsupervised learning in that it does not aim to learn patterns or structure in the data.
Reinforcement Learning from Human Feedback is a promising approach to improve the robustness and exploration in RL by collecting human feedback and incorporating prior knowledge of the target environment. The idea is to communicate complex goals to RL systems by defining goals in terms of human preferences between pairs of trajectory segments.
This approach can effectively solve complex RL tasks without access to the reward function, including Atari games and simulated robot locomotion, while providing feedback on less than one percent of our agent's interactions with the environment.
This reduces the cost of human oversight far enough that it can be practically applied to state-of-the-art RL systems. To demonstrate the flexibility of this approach, researchers have shown that they can successfully train complex novel behaviors with about an hour of human time.
These behaviors and environments are considerably more complex than any that have been previously learned from human feedback.
However, obtaining enough feedback of good quality from humans can be expensive. To mitigate this issue, researchers are exploring ways to rely on a group of multiple experts (and non-experts) with different skill levels to generate enough feedback. Such feedback can be inconsistent and infrequent.
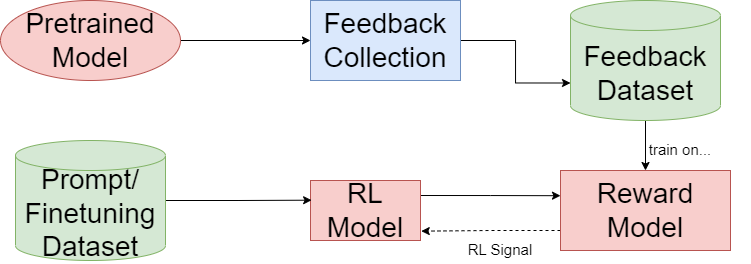
To address this, researchers have built upon prior work and extended the algorithm to accept feedback from a larger group of humans, while also estimating each trainer's reliability. This approach addresses the case of some of the trainers being adversarial, and having access to the information about each trainer's reliability provides a second layer of robustness and offers valuable information for people managing the whole system to improve the overall trust in the system.
RL algorithms use dynamic programming techniques to solve MDPs. The main difference between the classical dynamic programming methods and RL algorithms is that the latter do not assume knowledge of an exact mathematical model of the MDP and they target large MDPs where exact methods become infeasible.
Reinforcement learning is studied in many disciplines, such as game theory, control theory, operations research, information theory, simulation-based optimization, multi-agent systems, swarm intelligence, and statistics.
In the operations research and control literature, RL is called approximate dynamic programming or neuro-dynamic programming. RL has also been applied successfully to various problems, including robot control, elevator scheduling, telecommunications, backgammon, checkers and Go (AlphaGo).
Two elements make RL powerful: the use of samples to optimize performance and the use of function approximation to deal with large environments. Thanks to these two key components, RL can be used in large environments in situations where a model of the environment is known, but an analytic solution is not available, a simulation model of the environment is given, or the only way to collect information about the environment is to interact with it.
Subscribe to EverEvolve
<100 subscribers
guoyangzhen.github.io is the home page from KongsenYoung's personal blogs and researches about AI, Cognition, Sciences.