
奥莉薇雅·索利斯是一位信息设计师、研究者以及Sharelabs的活跃合作者,她目前的工作主要是为不同组织带入数字解方。Sharelabs是一个赛尔维亚的研究与数据调查小组,探索当代科技与社会的交会。
Olivia Solis is an information designer, and researcher. Her current work mainly focuses on bringing digital solutions to different organizations. She is an active collaborator at Sharelabs, a research and data investigation group that explores the intersection of technology and society in the current times.
演讲摘要
“剥削取证”是一组地图和文件,这些地图和文件是SHARE lab在过去几年的调查的结果。这些地图将帮助我们探索当代技术黑匣子及其分形供应链不可见的面向,揭示各种形式的隐藏劳动以及对物质资源和数据的利用。
有许多理由使我们应该对Facebook的算法工厂中所隐匿的黑匣子感兴趣。比如他们中介并记录我们的每一次互动,以及我们最私密的个人交流、行为和活动。 在这些隐性的墙内,算法每时每刻都会决定哪些信息将出现在我们的信息领域中,什么样的内容将成为我们现实的一部分,以及什么将被审查或删除。 不仅如此,这些黑匣子还定义了新的劳动和剥削形式,一方面它为拥有和控制生产资料的所有者创造了巨大的财富和权力,另一方面使得使用者经常生活在贫困线以下,这样就在拥有者与使用者在之间造成了巨大的经济差距。在Facebook算法机器的各个层次中,隐藏着一些潜在的侵犯人权的新形式,这种新形式的剥削方式与操纵机制每天影响着数十亿人。
我们每台联网设备和构成这些系统的庞大网络基础设施,在分形生产链,资源开发和能源消耗的无形立面背后都隐藏着许多有趣的故事。隐藏在无形限制区域中的无形劳动——从外包公司数据挖掘的深坑到全球数字劳动的无形工作空间——是AI系统解剖学的关注焦点。通过Amazon Alexa这个集中式的人工智能系统,我们的调查地图将引导观者经历网络设备之诞生、存在、死亡,展示其延伸的解剖结构和各种形式的利用方式。
Exploitation Forensics
Exploitation Forensics is a collection of maps and documents created as a result of investigations conducted in the last few years by the SHARE Lab. The maps will help us to explore the invisible layers of contemporary technological black boxes and their fractal supply chains, exposing various forms of hidden labour and the exploitation of material resources and data.
There are many reasons why we should be interested in the black boxes hidden within Facebook algorithmic factory. They mediate and record our every interaction, our deepest personal communications, our behaviour and our activities. Within these invisible walls, in every moment algorithms decide which information will appear in our infosphere, what kind of content will become part of our reality and what will be censored or deleted. Moreover, these black boxes have defined new forms of labour and exploitation and have generated an enormous amount of wealth and power for the owners of the invisible immaterial factories, creating a large economic gap between those who own and control the means of production and the users who often live below the poverty line. Somewhere hidden deep under the layers of Facebook’s algorithmic machines are new forms of potential human rights violations, new forms of exploitation and mechanisms of manipulation that influence billions of people each day.
Each of our networked devices and the vast Internet infrastructure that constitutes those systems, hide many interesting stories behind the invisible layers of fractal production chains, exploitation of resources and energy consumption. Invisible labour hidden within invisible restricted locations – from the deep mine holes over the office boxes of outsourced companies to the invisible working spaces of digital labour around the globe – is the focus of interest of Anatomy of an AI system. The maps will guide visitors through the birth, life and death of one networked device, based on a centralized artificial intelligence system, Amazon Alexa, exposing its extended anatomy and various forms of exploitation.
https://vimeo.com/386621540
第四届网络社会年会 奥莉薇雅·索利斯:剥削取证
剥削取证
文/奥利维娅.索利斯[Olivia Solis]
本文根据奥利维娅·索利斯在2019年第四届网络社会年会 | 网民21:超越个人帐户上的讲演整理编译而成。本文首发于中国美术学院学报《新美术》2020年2月号。
我将为大家介绍“共享实验室”[Share Lab]的工作。“共享实验室”是塞尔维亚的一个研究与数据调查小组,一个由创作者、研究者、律师、取证者等多方协作的非正式团体。实验室的工作始于大约五年前,一直以来致力于通过可视化图表去揭露互联网不为人知的隐匿面,去探索隐藏在屏幕与界面背后的不可见的事实及其复杂性,试图破译元现实[meta-reality]的黑箱。
一、看不见的基建:网络架构与在线跟踪
我们的第一项研究是针对塞尔维亚当地的互联网服务提供方[ISP]展开的研究。我们绘制了一系列可视化图谱以呈现不同网络的技术基建、线路和数据中心,以及所有节点的分布与连接。[1][图1] 当这些结构被可视化以后,我们就能发现它们的技术弱点所在,也能发现信息过滤和审查发生之处,以及数据存储量和收割量最高之处。于是我们对技术弱点和可能的信息管控过滤点进行了研究。
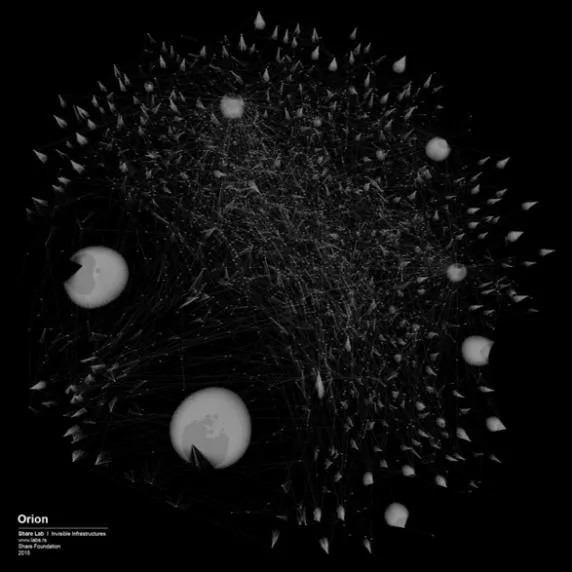
[图1]塞尔维亚网服供应商Orion的基建可视图
我们做过一些关于我们的政府如何通过收集数据干预公民的研究。但问题在于除政府之外,还有谁拥有获取我们数据的途径?是否有其他公司潜伏在我们的日常网络生活中?于是,我们对塞尔维亚国内访问量最高的几百个网站进行了取样,检查了出现在这些网站上的所有跟踪器[trackers],比如实时跟踪数据的信息记录程序[cookies]。除了经常被访问的新闻门户网站知道你的行踪外,还有更多来自第三方公司的无声监视者,如90%的网站都安插了来自谷歌[Google]或脸书[Facebook]的信息记录程序。正是这些网络的数据主掌握着互联网流量数据的霸权。就算你没有脸书的账户,或避免使用谷歌服务,它们仍然化身跟踪器,无处不在地潜伏于普遍性的网站中。
很多人对此缺乏思考,他们会说:“好吧,但这只是些元数据[metadata]而已。”其实,元数据的威力以及有能力处理这些数据的人,比具体数据所指涉的内容要更为强大。一旦能根据数据识别出行为模式和异常状况,就能推测人们的动向。
二、元数据调查:结构透视与异常监测
在下一项研究中,我们投身于分析一家名叫“黑客团队” [Hacking Team] 的公司的内部通讯电子邮件。这家公司为不同的政府机构和公司提供监视技术方案,其数据被维基解密[Wikileaks]公开在网上。通过往来邮件的基本参数和时间标记,我们仅依靠电子邮件的元数据创作出了可视化图表,[2][图2] 从这些表上可以看出行为模式及异常现象,这些比具体的邮件内容更有洞见力。我们从中可以了解到关于这家公司的方方面面,比如,公司的组织结构为何,谁是老板,他/她什么时候遇到困难,公司什么时候遭遇公关危机,公司成员什么时候开会,以及他们在世界各地的什么地方会晤,等等。这一调查结果令我们对元数据的潜力感到震惊和害怕。如果仅凭我们的一己拙力就能够从元数据中提取这么多有效信息,那么,对于那些拥有无穷权力、技术和资源的公司来说,还有什么是办不到的?这一切将我们引向了最大的研究项目之一:对脸书算法的研究。

[图2]模式识别与异常检测:D.Vincenzetti每小时发送邮件的比对热图(2014年6月、9月和10月)
三、监控资本主义:人力金字塔与算法工厂
脸书或许是这个世界上监控资本主义的最典型案例。脸书拥有巨大的用户量,而这些用户量都被转化成了利润。这是如何发生的呢?一方面,这个平台上每天都有如此多的交互和内容产生,生成海量的数据。另一方面,在这个人口数量比中国更大的帝国中,每年有170亿美元的产值,,而这些钱并不属于使用它的人。那些用户贴出的度假照片和不同人的点赞如何就转化成了利润呢?
这个黑箱定义了一种新的劳动力形式和剥削方式,并在生产工具拥有者(脸书平台的创造者)和制造财富(数据)的劳工(用户)之间制造了巨大的鸿沟。我们必须明白,当我们使用这个社交平台时,通过点赞、发帖、上传内容,我们实际上是以非物质劳动力[immaterial labor]的形式在工作。如果我们每人每天花20分钟时间使用脸书,那就是每天为这家公司贡献3亿无薪工时。作为数字劳工[digital labor],我们是如何为脸书这样的公司去创造了实际价值?
两年前我们提出了算法透明度 [algorithmic transparency] 的概念,尝试回答是否有可能实现算法透明性,以便去认识黑箱内部的大公司沟通与决策机制,以及各种算法影响用户生活的方式。
我们首先研究了脸书的董事会成员及其关系网。这是一群来自硅谷的白人男性,拥有相似的教育背景,与各行各业都有紧密联系,也有明显的“旋转门效应” [revolving doors],即他们在成为脸书高管之前曾就职于谷歌、微软[Microsoft]或其他类似的大公司。而后,我们又做了另一项工作。我们抓取了在领英[Linked-in]上宣称自己有过脸书工作经历的用户的信息,试图对这部分人进行研究。我们发现底层职位的普通工程师们,背景的确较为多元。他们出生于不同的国家,教育背景各异。然而随着工资等级提高,“旋转门效应”就越来越明显。处在最高层的,依旧是那些来自于加州的白人男性。这个帝国,只是一个看上去多元背景的、跨国界、跨种族的帝国。
这项研究只是证实了这家公司的精英主义和美国中心制的本质,及其跨界影响力。然而我们尚不能以此洞悉算法,随后我们制作了这张信息量巨大的图谱。[3][图3] 图片的左边部分显示的是用户向脸书输入的数据,图片的右边显示的是如何将这些数据作为产品进行买卖。
图片的最左侧显示的是数据收集,从上至下可以看到三部分数据来源。第一部分是用户的动作[actions]和行为[behaviors],即点击、点赞、分享、写评论、增加内容与内容互动等。第二部分是用户的个人主页信息[user profiles]。这部分和第一部分的不同之处在于,脸书并不真的在乎个人提供的基本资料。它们知道人们在公众面前描述自己时,往往不完全诚实。人们想要打造的个人形象与实际情况常常并不相符,因此并不当真。但脸书非常重视用户的行为和每一步动作。第三部分是数字足迹[digital footprints],即用户在设备上留下的痕迹和泄露的信息,包括浏览的内容、地理位置信息、实际操作等。因此它们可以通过设备收集到大量信息。脸书公司旗下有一系列的应用程序,如即时通[WhatsApp]、脸书[Facebook]、信使[Messenger]、照片墙[Instagram]等等。当用户在手机上安装了这些应用程序,就授予了这些程序一系列的许可去获取手机上几乎所有的信息。这个信息量是巨大的。即使你没在使用脸书,甚至都未注册任何账户,它们仍然能通过某种方法跟踪到你。我们也别忘了,就算用户没有安装以上应用程序,它们仍然通过跟踪器在别的网站上进行着隐身的数据收割。更何况,除了脸书,旗下还拥有很多家公司,同时也与别家公司拥有伙伴关系,出于商业目的进行着数据交易。因这些公司有能力收集巨量的数据,也有能力通过买卖信息和交叉比对进行数据分析。

[图3]脸书算法工厂调查结果的整体可视图
图片的左侧一栏让我们明白了数据收割的范围及类型,以及进入数据的多重途径。不过,让我们看一看这张图的最右侧一栏,看看脸书定位目标市场[targeting]的不同手段。
脸书将用户数据以不同的方式买卖给广告主。一些用户的主页信息卖得比另一些用户的贵;一些地区的数据卖得比另一些地区的贵。在美国交易的成本就比在塞尔维亚更高,因为塞尔维亚较为贫困,人们较少在网上交易。这样一种买卖方式其实与从前的传统媒体交易无异。在过去,能把一个杂志卖给广告商,是因为这个杂志拥有一批读者。也就是说杂志本身的内容并非真正的产品,它所覆盖的读者群才是。今天的脸书也是类似的状况,只是现在其产品可以定位到精确的个体而非模糊的群体。也正因为这样,买卖变得可以量身定制。
然而,脸书是如何对用户群进行分类的呢?目标定位的途径有很多,比如基于人际关系、人口统计资料、用户兴趣和行为模式等进行定位。而这些都来自对用户数据的处理和分析。理解算法究竟如何处理数据,是理解脸书每天如何操纵和影响数十亿人的剥削机制的关键。呈现在眼前的是输入端和输出端,但我们想破译中间过程,即数据处理的算法黑箱。我们尝试过使用假账户进行了一系列实验,但很快就意识到我们不可能拥有“无菌的环境”去执行测试。设备、浏览器、地理位置、网络提供商,种种参数都会影响结果。因此我们转移了目光,聚焦于研究脸书已公开的专利。这项研究让我们更好地认识了发生于其中的内幕。
根据脸书的专利,数据库被分为三类:“动作库”[Action Store]、“内容库”[Content Store]和“连结库”[Edge Store]。“动作库”维护着描述用户动作的信息,如一次登陆或点赞;“内容库”存储着代表各种内容的对象,如一张图片或一条评论;“连结库”存储着描述用户与其他对象间联系的信息,如一个用户对一条推送的转发。这三类数据库构成了脸书工厂的基本建筑,源源不断地喂养着脸书的社交图谱 [Social Graph] 。社交图谱连接起所有的节点和关系,纳入一个总体巨构中。
基于动作的目标定位主要采用的是模糊匹配算法[Fuzzy matching algorithm],根据用户的动作喜好和广告的概念属性来进行模糊匹配;基于内容的定位通过话题和关键词提取,并根据最高位的排序来精准定义内容,进而匹配出投放给用户的广告;基于社会关系的定位根据相似的属性对用户进行分群,并根据种子用户 [seed users] 的属性对其投放广告和定制内容,进而去影响这些种子用户所辐射的次级用户。这个过程可被视为一种新的审查形式。
同时,脸书还有一系列的处理器和算法试图把用户主页信息推给广告主。但是,在广告主眼里,并非所有的用户信息都拥有同样价值。高消费者和冲动型购买者才是符合需求的目标用户,因而这些人会被标上更高的价格。
以上一系列研究使我们意识到,想要图解整个系统的运作是几乎不可能的。因此,算法的透明度是一个无法解答的问题。不妨将这张图作为对部分现实的某种诠释。此外,我们所能获取的这些公开专利都已陈年。我们永远无法对现实中发生的事绘制出新鲜的图像。这张图就像是打着一束手电筒的光在黑黑的森林里摸索,找到一些树木,知道一些小树林之间是如何相互连结的,但永远无法成为一张看清全局的大图。另外,与那些时时刻刻在开发和进化的大公司所拥有的资源数量相比,我们作为独立研究者所投入的资源和时间都是九牛一毛。这些系统变化得太快,而我们认识它们的能力十分有限。这张图的价值在于它的稀有性。这是为数不多的试图破解算法运作机制的尝试之一。就像古时候的地图一样,那时大陆还未成形,新的土地等待着被人发现。
四、神经网络:数据培训与嵌套剥削
机器学习和人工智能正变得越来越普遍。非物质劳动力的概念也不再以它原本被定义的方式运行。我们已经不再是劳动力,因为在这个过程中,用户成为了原料,算法才是真正的劳动力。

[图4]人工智能系统解剖图
我们不妨思考一下亚马逊智能助手[Amazon Echo]这样的声音交互人工智能界面。[4][图4] 这件生活在家中的人工智能机器,仅仅是浮在水面上的冰山一角。艾莉克莎[Alexa]的大脑可并不藏在这件披着塑料外衣的制品中,而是在遥远的数据中心里。也就是说,你并非真正享有所有权。购买这一商品只是允许亚马逊[Amazon]冠冕堂皇地登堂入室,潜入你的家中,而你将沦为一名无偿培训这一神经网络 [neural networks] 的工人。对于人工智能而言,用户的作用发生了变化。用户并不创造内容,而是在照料这些物体,培训人工智能。这一产品不断地在世界各地的终端接受学习。这个过程的每一步中它们都在剥削和读取我们的信息。我们所做的就是对这个过程中发生的网络技术性细节进行绘图。
接下来让我们涉足神经网络的黑箱,窥探一个神经网络的诞生背后所需的隐形劳动力。培训这样一个人工智能,需要海量的声音样本,而所有这些声音内容都需要被标记,以确保它们包含可以被机器理解的元数据。然而谁拥有制造这些大规模数据集的权力?谁享有这些内容和数据?不出所料,仍然是那些长期收集数据的巨头玩家:脸书、谷歌、微软、亚马逊。它们垄断了数据的所有权,进而垄断了对人工智能系统的培训和制造。
另一个值得关注的问题是,人工智能系统从来都是抱有偏见的。英语永远会是主导语言,因为英语的语音资料档案最多,也最为广泛理解。而要想培训网络,就得有这样一种能被正确标记的易于理解的数据。结果就是那些小众的语言,弱势的文化就更容易被淘汰,主导文化将变得更为强势。这将导致文化之间鸿沟会越发巨大。
让我们退一步谈谈这个物体本身。它有其自身的物质性,所有成分都来自地球。图上呈现了这个物体的计划性报废的短暂生命周期,从诞生、存活到死亡及至死后生活。一切始于地球,也归于地球。从这个星球的矿洞中提取出来的矿物质金属,最终以废料的形式弃还地球。以苹果手机[iPhone]为例,其75%的成分都来自元素周期表上的元素。在20世纪以前,我们鲜少使用这些元素。如今,它们却是构成一台手机75%的物质。且稀土金属对生态环境影响巨大,因此并没有多少国家愿意去采掘,而中国则身处稀土元素采掘的前线,这是以生态代价换来的经济优势。有趣的事实是,制造一台苹果手机需要全球配合的复杂供应链和装配运输线:从原料运输到部件组装,将一台手机所有材料运到深圳工厂的路程相当于从地球往返月球两次的距离。这就是今天制造业的新标准和新现实。我们认为,理解这一过程对于认识我们当今生活的世界至关重要。
运用马克思的理论,我们绘制了这个三角图示 [图5][图6]:经济中的主体和客体。原材料和劳动力配合制造出了一个产品,而这个产品成为了下一个三角中的原材料。一个元素成为一种金属;金属变成一个元件;元件变成了一个配件。每一轮过程都与劳动力剥削同时发生。对劳动力的层层剥削加剧了世界的不平等性,在链条顶层的是坐收渔利的亚马逊总裁杰夫·贝佐斯[Jeff Bezos],在底层的是那些日薪只有一美元的矿工。这一嵌套式的剥削过程不仅仅是对人的剥削,也是对地球的剥削。那些要花上数十亿年时间形成的自然资源在生产和开发的过程中被瞬间耗尽。这就是一个产品的诞生。当一些人在滑动手机屏幕的时候,另一些人正在采矿。而我们总是倾向于把玩光鲜的新产品和新技术而忽略背后不为人见的过程,或假装这些问题并不存在。我认为,我们需要着手去创造一个新的等式。
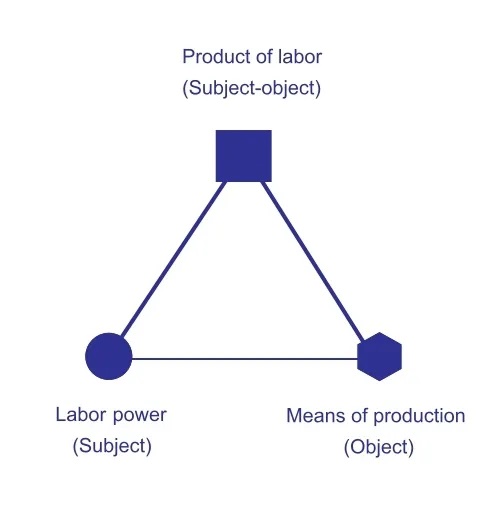
[图5] 马克思经济的主客辩证三角图示

图6 谢尔宾斯基三角
最后我想跟大家说,人工智能的竞赛是一种对主导地位的竞速争夺,也就是说,一些拥有权力的人和没有权力的人之间的争夺
(蒋斐然 编译)

本文作者奥利维娅·索利斯在2019年第四届网络社会年会“网民21:超越个人账户”现场
脚注
[1]本专题高清图片参见Share Lab网站Invisible Infrastructures:https://labs.rs/en/as/
[2]本专题高清图片参见Share Lab网站Metadata Investigation:Inside the Hacking Team: https://labs.rs/en/metadata/
[3]该图谱的高清图版及局部细节图请参Share Lab网站:https://labs.rs/en/quantified-lives/
[4]该图片高清图版参见https://anatomyof.ai/img/ai-anatomy-map.pdf

