第一届网络社会年会 时间:2016年11月14日上午 地点:中国美术学院象山校区水岸山居会议室 讲者:全喜卿(Wendy Chun) 布朗大学现代文化与媒体专业教授 译/卢睿洋 校译/黄孙权

各位早安,非常感谢主办方邀请我参加第一届网络社会年会,非常振奋,我希望能和大家分享我正在做的项目。 我现在正在写一本书,关于一些列名为数据歧视(discriminating data)的算法。数据歧视研究力图囊括人文领域、艺术、计算机科学、社会学等,来发展批判性的算法研究。我将简明扼要地把精髓告诉大家:通过网络,尤其是网络科学,我们现在所经历的是身份政治的激增,是范畴的激增,比如种族、性别差异、阶级、性存在,它们由于关联(correlation)和代理服务器而繁殖,这些事情通过最近的美国大选变得十分明显了。 重点是,我们绝非处于后种族、后性别状态中,而这种状态是奥巴马当选时美国为之欢庆的东西。举个简单的例子,我们来看看邮政编码分析。这是对我居住的波士顿南瑞区的邮政编码分析。
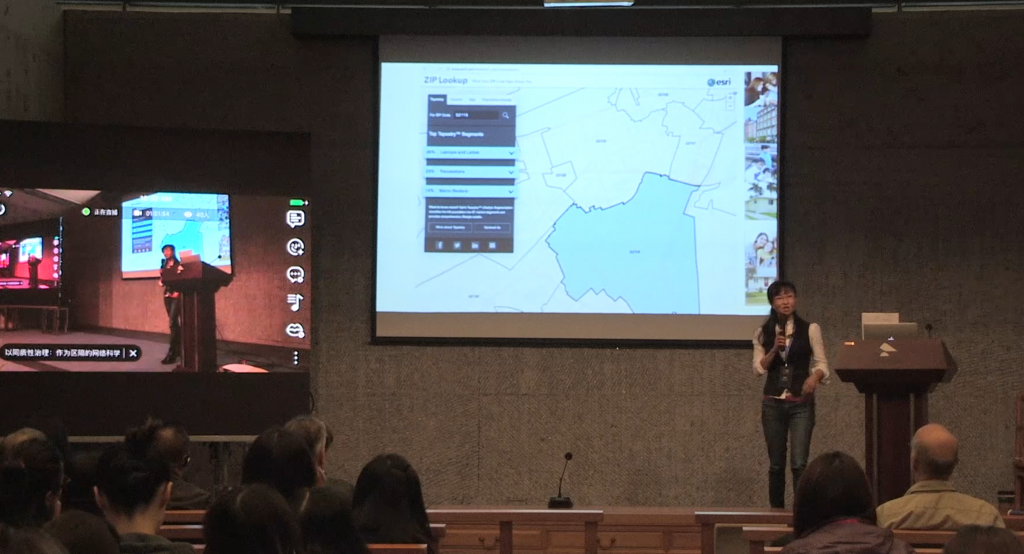
邮政编码正在被用来确定越来越多的事情,比如你将支付多少汽车保险。有很多研究将邮政编码与几乎所有事情关联起来,从肥胖问题到犯罪问题。你能看到,在这个区生活的主要群体被称为“笔记本电脑与拿铁咖啡”,这些范畴看似无害,实则不然。 在这里你能看到两个群体鲜明的区分。很多人指出,这些范畴的作用是划清种族、性别差异、性存在的范畴,而某些情况下,这样做在美国其实是非法的。更要紧的是,这些范畴是一种身份交集的代理服务器,尤其是种族与阶层的交集。如果你注意“西班牙语居民区”和“美国梦想家”这两个范畴,在种族方面它们几乎一致,但它们的阶层流动性却有细微差别,而这在分析和整合它们时是很重要的。 这些范畴的危害在于,它们似乎只是描述,但实际上却是在规定,它们宣称只是发现了区隔,实际上却是在建立区隔。 美国银行会基于邮政编码分析来决定是否给某人贷款。美国的警方预算越来越吃紧,所以他们基于邮政编码一类的东西来做预测从而决定警力资源分配。凯西·奥尼尔(Cathy O' Neil)在她的著作《数学杀伤性武器》(Weapons of Math Destruction)中非常出色的描述了这些问题。她先前是一名数学教授,之后转为量化数据科学家,她参加过占领运动,而在这本出色的著作中,她勾勒了大数据算法如何延续着不平等。她非常强调透明度,而这些算法最有害的地方正是不透明,你根本不知道你是如何被判别的。所以我们需要更多透明度,才可能干预这些算法,理解我们与它们的关系。 她非常强调透明度,正如利奥塔( Jean Francois Lyotard)在许多年前就指出的:“这些算法事关效率而非正义”。透明度很重要,但还不够,我希望大家思考一些略为不同的东西,即物质层的区隔面与网络层面的区隔之间怪异的反馈循环。如果说网络制造了回音室效应(echo-chamber),部分原因是它建立在美国的居住隔离模式之上。它的基本假设是,物以类聚人以群分。所以在网络科学的核心处是同质性(homophily),也就是一种我爱和我相同者的观念。 这是网络科学的基本准则。所以,我的问题是,如果我们重新思考关联性,如果我们替换同质性,如果我们破坏同质性,如果我们拥抱自己在这场戏剧中的角色(这场戏剧被苍白地称为“大数据”)如果我们运用不同的网络,如果我们创造新的剧本,而非仅仅扮演“笔记本电脑和拿铁咖啡”,情况会有什么不同?

第一部分要谈“机器学习和洗钱”。最近告示牌(PinBoard)发布了如下推文“机器学习就像偏颇的洗钱”,被转发了上千次。之所以如此,是因为它似乎一语道破了不断增长的对机器学习和算法的伦理与所谓中立的怀疑。 来看看最近脸书出的乱子,它最近出人意料地解雇了所有编辑,替换成算法编辑,《卫报》评论说,算法开始发疯。在几分钟内,就出现了两个假的头条故事新闻,它说保守派主持人凯利( Meghan Kelly)(她为非常保守的新闻频道福克斯新闻工作)被福克斯解雇,据说因为她要支持了希拉里。 第二个热点故事是件真事,一名男子用麦当劳的三明治自慰的视频流传在脸书上,脸书着力审查喂奶的图片,但却让这个视频蔓延开来。在当周,还出现对犯罪预测的指责。尤其是民权组织联盟发表声明谴责这种技术。这些组织说,问题在于内嵌在这些系统中的犯罪数据,它是非常不完全的,而且容易被种族偏见所操作或制造麻烦。 这只是两个例子,其他的例子中还包括哈佛大学研究者的著名案例,在谷歌上搜索听起来像黑人的名字,就有25%以上的几率搜到有关犯罪记录的广告。美国法庭用于判断某人可能是惯犯的软件以及有些法庭用于决定一个罪犯是否假释或判刑多久的系统,都对少数族裔抱有偏见。 这些例子综合起来,问题似乎在于“坏数据”。 所以,据说我们需要的是更洁净的数据,需要清除了种族偏见的犯罪数据,数据库中需要有更多黑人民谣,我们的技术工业需要更多样 。换言之,问题仍旧是数字分隔(digital divide)。 虽然缺乏多样性的确是技术工业的一个问题,但解决之道并非所谓更好的数据,毕竟开发这些程序就是要解决政治、种族偏见。脸书之所以解雇了它的人类编辑,是因为它被指控对保守新闻势力有偏见。之所以转向机器学习,因为人们以为,假如我们运用了正确的技术,我们的政治问题就会消失,某种意义上,科技可以解决政治。这种观念正是这些系统的驱动力。所以,许多分析人士指出,问题不仅仅在于纳入数据或排除数据,而是差异如何被隐秘地编码进这些系统中。通过使受保护的个人可识别信息明晰化,大数据威胁着隐私保护。所以如今歧视的行为并不需要由某个组织主动做出。 来看看芝加哥警方的头号名单,为了对付不断增多的杀人犯,芝加哥警方运用社交网络分析,得出了一份近420人的名单,这些人有可能杀人或被杀。当你掌握了这些,你就可以去找到他们说“你处在被谋杀的威胁中,赶快离开这里”,这种做法像极了一部叫《疑犯追凶》(Persons of Interest)的美剧。估计芝加哥警察是电视剧看多了。 这张头号名单揭示的重要问题是,它并非基于你的行为,而是基于你所认识的人的行为。它实际上基于人们的关系串,基于你所引用的人。所以,由于你的朋友和朋友的行为,你成了嫌疑犯。所以种族并非被特别考虑在内的因素,因为它已经内在于社交网络范畴中。 在众多研究中一项针对推特的研究揭示出,基于你点的赞、你粉的人和粉你的人,你的年龄、你的政治倾向一类的事情是非常容易推测出的。在网络分析中最可预测的是双向关系。 所以,在网络的区域中,时时刻刻你其实都被捕捉。通过你的邻居,通过为你点赞的人,即便你自己什么都没说,你也被捕捉了;即便你什么都没做,你也已经被记录在案了。这是因为,如我在《更新到原样:习惯了的新媒体(Updating to Remain the Same)》一书中所说,你的历史已经不再属于你,你的身体不再是单一的,不再以皮肤为界,而是拓展到了那些为你点赞的人的范围里。你的身体通过你的行为与他人相连,连来连去我们成了奇美拉怪兽。你的行为再也不是单独的,而是症状性的。所以我越发认为大数据是精神分析的私生子:在大数据的世界中,没有事故、没有口误,所有行为都是症状性的,所有行为都揭示出更大的所谓无意识图式。 精神分析的重点是改变患者,而网络科学也是通过各种发现来改变你的行为,虽然它没有明说。但网络科学为自己辩护的方式是:“我们仅仅提供人们所需”。所以大数据的所作所为是发掘人们的需求。 但这些算法起到了延长它所发现的行为和歧视的作用。所以它们不仅仅是在描述,也是在规定,换言之,它们是述行性的(performative)。正如阿格雷(Philip E. Agre) 所说(他曾是人工智能研究者,后来成为一名信息理论家,他在80年代就讨论过捕捉系统),这些系统生产它们所发现的东西,它们用模型来塑造现实,它们把自身的连接方式强加于现实。所以在美国一个显而易见的例子是公共系统中标准化考试的应用,这意味着教师们越来越按着考试来教学。这些系统以为自己只是在采样,实则在塑造现实。进而,预测式的捕捉模型创造了它们所预测的结果。它们成了自我应验的预言家。所以,芝加哥警方的头号名单并没有使得谋杀率下降,而它产生的效果是,如果你名列其中,那么你假如开抢,你被捕的几率比不在名单中的人高2.8倍。所以处在名单中意味着你更可能被捕,而且另一方面,警察为了防止你被别人谋杀而提前来访,会让你更可能被谋杀。据某篇文章说,警察来访过后,某人邻居发现,他很担心自己成为向警方告密的人。所以这些网络创造了它们声称仅作描述的现实。 网络能创造、导致它所想象的现实,能成为自我应验的预言家。它们能重塑、重组它们所描述的现实。希利(Karen L Healy)等人已经提出网络是述行性的。 因为网络是述行性的,也许它能塑造一个别样的世界。述行性并非仅仅让现实与理论一致,就其丰富的内涵,述行性也描述持续的行为和重复会巩固言说或身份。如巴特勒( Judith Butler)和德里达( Jaques Derrida)多年前所说,述行性的言论基于重复的行为或共同体。巴特勒著名的命题是,性别本身就是述行性的。性别看上去是自然而然的,但其实源于我们的重复。我们认为是自然的、本质的东西是靠持续的一系列行为来维持的。我们认作自身内在特质的东西,是我们通过身体行动来期望和生产的。关键在于,后来这些姿势被遗忘了,并且凝固在看似天然的身份中。阿赫美(Sara Ahmed)尖锐地指出,规范的作用就像是重覆性劳损。 连接究竟是什么,它就是习惯性重复行为留下的痕迹,就是重复行为的结果。我们来想想在社交网络比如脸书上,朋友关系是如何被维持的。这些网络基于你的持续行为,它们会提醒你对某人说“生日快乐”。它们希望你重复这些行为,进而它们就能度量、维持它们的朋友观念。我要再问一次,如果我们积极致力于网络的述行性,如果我们将自己视为剧场中的角色、这场叫做大数据的哑剧中的角色的话,会有什么改变? 迎接这个挑战,首先我们要意识到我们在网络中说话的方式是无声的行为。如今,重要的不是你说了什么而是你做了什么,因为我们的行为持续不断地被采样,我们必须意识到,自己的行为不仅仅是单一的,它们被连接起来, 阿格雷称之为行为的语法。所以我们总是通过看似无声的行为在言说。 为了迎接这个挑战,我们还需要避免仅仅贬低或夸大大数据。不要把大数据不准确的预测当成是我们的独特性或不可预测性的体现。当亚马逊给了坏的推荐,并不意味着我是特殊的。这些系统是有意地给出随机推荐的,随机推荐是有意植入其中,是为了让这些算法不要太过吓人,它让我们感觉自己是特殊的,同时又自发地购买。设计者希望把自发性植入系统中。 举个例子,塔吉特(Target)百货是美国一个影响力惊人的零售连锁店,他们发现通过算法测定你是否怀孕是非常简单的。那时你会倾向于使用无香型洗液并要摄入维生素B6。他们用数据模型来计算你的孕吐。但为了不让算法吓着你,他们还会给你推送汽油优惠券。 大数据是言过其实的,所有的科技也是。如果你身处硅谷你就知道,硅谷的存亡都系于演示。 所以我们要意识到的是,真正的大数据提出了令人着迷的计算问题。比如,如果只能阅读一次,你会如何分析数据。它还提出了关于因果性的重要问题,因为通过数据分析,任何关联性都有可能存在。比如一篇文章指出,肥胖像病毒一样在朋友间传播。这被认作是网络分析中典型的坏案例,因为显然肥胖不是一种病毒,你不会被朋友传染,它也没给出任何实质的疗法,除了在你的朋友变胖之前赶紧远离他们。这里,问题不仅在于假关联性,还在于多重关联性。所以這是与邮政编码研究的相反情况。 所以大数据带来的问题是,真实(real)的与为真(true)之间的关系是什么?如果任何事情都显得是真实的,如果任何关联性都能被发掘出来,那么什么是关键的?而且,进一步的问题是,为真的东西与激发了行为的东西之间的关系是什么?这一系列的问题源自我在布朗布朗大学与一位计算机科学家和数据统计学家的研究项目。 这在人文领域和物理、社会科学领域引起了共鸣。为了解决这些,我们还需要意识到,预测与现实之间的缝隙正是行动和政治的场所。预言家可以自我应验也能自我抵消。比如全球气候变化问题的模式。如果我们认为它说的是真的,我们就会想办法不让它成为真实的。如果它是真的,我们会行动,所以也就无法知道它预测的是真实的。的确,如果我们等待着,看看它是否是真实的,这就错过了斗争,相当于确保全球气候变化的发生。 所以,模型可以揭示出被抵制的现实,模型可以帮助我们塑造未来。在这个意义上,我们也能思考投票与投票结果之间的缝隙,那是政治行动的空间。 所以,我们需要解读剧本,分析我们在媒介角逐之中的设定,而这场角逐就是网络科学的实验室。 第二部分:同质性,或者是物以类聚者被一网打尽。 简单明了地问一句,什么是网络科学? 在最基本的层面,网络科学捕捉、分析、连接、利用、工具化、推敲联系。它是关于联系的科学。它根本上是跨学科的,但它主要结合了量化社会学、计算机科学和心理学。 如今,以网络科学为名的宣言都口气很大。网络科学家巴拉巴西(Albert-László Barabási)说:“网络科学消除了人们对心理学的需要”。以前如果你要理解人们的行为和动机,你需要有心理学家证,而今你可能要攻读计算机科学。这是因为网络科学加上越发犀利的数码技术把我们置于一个巨大的实验室中,它的尺度、复杂度和精细程度超过了科学曾经遭遇过的一切。 这个实验室揭示了人们的生活节律,而这是更深的人类行为秩序的证据。这种节律可以被探索、预测,当然也能被利用。网络科学揭示了巨大的集体无意识,并将其装在一个数码鱼缸中。至关重要的是,当这些被揭示出来,网络科学也就翻转了世界,它将世界变为实验室。 换个角度看,网络科学正是詹姆森( Fred Jameson)说的认知绘图(cognitive mapping)的倒错版本。与其说网络是一种尚可想象的政治艺术形式,它发展新的器官,把我们的感知系统、身体拓展到新的不可思议的、甚至不可企及的维度(这是詹姆森对认知绘图的描述),不如说它终结了后现代。它终结了后现代的困惑,也就是终结了詹姆森所定义的在本真与为真之间的后现代两难,因为它把世界变成一张地图,因为它把本真性还原为系统性的真伪验证。 与詹姆森想象的认知绘图一样,网络的确驱散了后现代的迷雾,消除了本真与为真的差异。它揭露了个体与个体所处的社会之间的链接,从而消灭了后现代主义。但与詹姆森的想象不同的是,它并没有让人类长出新器官,我们并没有迎来新器官和新感知系统的美妙状况。相反,它将世界缩减为地图,它把人工智能模型的为真套在本真性之上,它把世界还原为实验室。网络科学把世界现象还原为节点与边缘,这张地图反过来又生产出图式,驱动着多样化的社交网络好友关系和金融危机的现象。

所以我们需要记住,网络、网络科学、网络图表是对极端简化的极端简化。这里有两步抽象化。第一步是应用的、认识论的,它创造了地图。它将世界现象还原为一系列的节点和边缘。第二步是纯粹的网络理论,也就是数学式的,它产生数学公式,从而再生产出在第一步中被抽象化了的东西。 所以,关键在于模仿即真。如果你能再生产出你先前所抽象的东西,那么你就逐渐掌握了因果性的基础。 网络科学主要基于网络算法、推荐系统和搜索引擎。网络科学的核心原则是同质性。同质性公理即相似产生联系,物以类聚人以群分,喜欢意味着喜欢所喜欢。这是一篇被引用最多的关于同质性的文章的摘要。 [caption id="attachment_1644" align="alignnone" width="810"]

麦弗逊(Miller McPherson),洛文(Lynn Smith-lovin),库克(James M Cook),物以类聚:社交网络中的同质性,Annu Rev.Sociol.2001.27:415-44。[/caption] 它说,同质性将社会和地理联系起来,事实上正是这样的网络观念给作为生态的网络的观念打下了基础。所以在网络科学的核心处,是一种生态的隐喻。 同质性是协同过滤算法的基础,协同过滤算法的操作方式是把用户归并成群集,它基于类似特征、类似意见来结构网络。举个简单的例子。
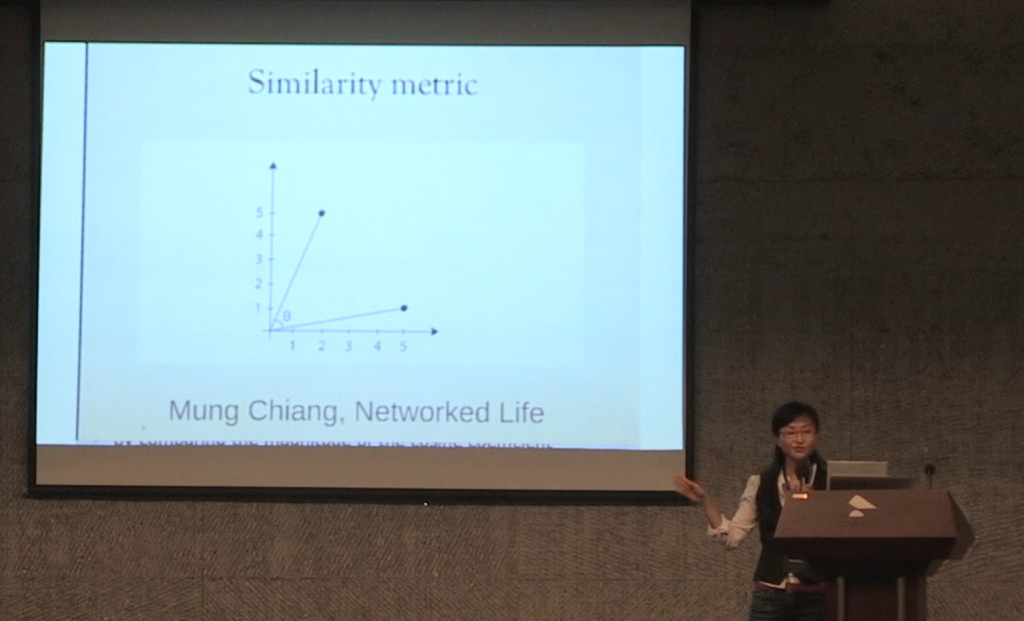
通过比较电影和用户之间的协同系数,这些连线可以表示不同用户对同一部电影的评分,同样也可以表示同一用户对不同电影的评分;比较这些协同率的级别,就能按差异最大的和最相似创造出电影和用户的邻居关系。然后再结合基于用户和电影的倾向性而预测评分的公式,创造出协同过滤算法的基础。 重点在于,你被置于一种基于你的强烈好恶的邻居关系中,所以你越反常越容易被预测。协同过滤算法结构网络的方式是制造群集,就如“邻居”一词所示,它是基于隔离和红线的观念的。 所以我们如今处在回声室中,这实在没什么可惊讶的,因为一种退步的身份政治观念正驱动着网络政治,驱动着网络科学和同质性。这是一本著名的网络科学教科书对同质性的定义。 我很尊敬乔恩·克莱因伯格( Jon Kleinberg)和他的同事,但大家看看这个定义是基于什么样的假设。

图片文字——同质性:规定社交网络结构的最基本观念是同质性——也就是人以类聚的原则。你的朋友并不是从潜在人群中随机抽样出来的。总体上看,你的朋友在种族、民族上与你类似;年龄也相仿,性格也或多或少类似,还包括居住地、职业、富裕程度、兴趣、信仰和观点,都与你相仿(伊斯利(Easley)和克莱因伯格(Kleinberg)<fn>Jon Kleinberg; David Easley (2010). Networks, Crowds, and Markets: Reasoning About a Highly Connected World. Cambridge, UK: Cambridge University Press. ISBN 0-521-19533-0.)</fn>。 所以,根本上,作为基本原则的同质性将它所划定的隔离强加给我们并将其自然化。 而且,同质性视个体而非机构成为区隔的原因。我们必须意识到区隔与同质性深刻的关联。拉扎斯菲尔德( Lazarsfeld)和默顿( Merton)1954年最先在《作为社会过程的朋友关系:实质分析和方法论分析(Friendship as a Social Process: A Substantive and Methodological Analysis)》<fn>Lazarsfeld, P. F. and Merton, R. K. RONKEYLAF (1954). "Friendship as a Social Process: A Substantive and Methodological Analysis". In Freedom and Control in Modern Society, Morroe Berger, Theodore Abel, and Charles H. Page, eds. New York: Van Nostrand, 18–66</fn>提出同质性这个术语,但在同一章节中他们还构造了异质性一词。 网络科学总是从这篇文章中引用同质性概念,但有一点被完全忘却了:他们的同质性概念基于对美国居民邻里关系中的区隔的分析。这并不令人吃惊。 而且斯菲尔德和默顿也并未将同质性假定为基本原则,而且他们也不认为同质性是天然的。事实上,这正是他们提出的问题,他们关心多样化的动态是可能的,异质性和同质性都是可能的。所以,同质性以及他们被引用得最多的章节(但并未正真被仔细阅读)仅仅是朋友关系中的一种情况。而同质性在当前的网络科学被视作常理,这正是对这段历史的遗忘。 从地图到模型,同质性不再被视为问题,而成了解决方案,它不再是需要掂量的东西,而成了自然而然的东西,而它正是内嵌在网络中的不平等的原因。把同质性当做起点,也就预定了终点。如果设定了同质性,那么区隔就会复苏。作为基本原则的同质性强加了它所划定的区隔。 把同质性当做显然的和自然的,克莱因伯格和伊斯利认为最容易发现的同质性效应就是邻里和城市在民族和种族上的同质。所以区隔被当做同质性自然而然导出的一个例子。 为了解释这一点,他们转而援引托马斯·谢林(Thomas Schelling)著名的区隔模型,它显示了地区性的同质性如何产生全球范围的区隔图式。
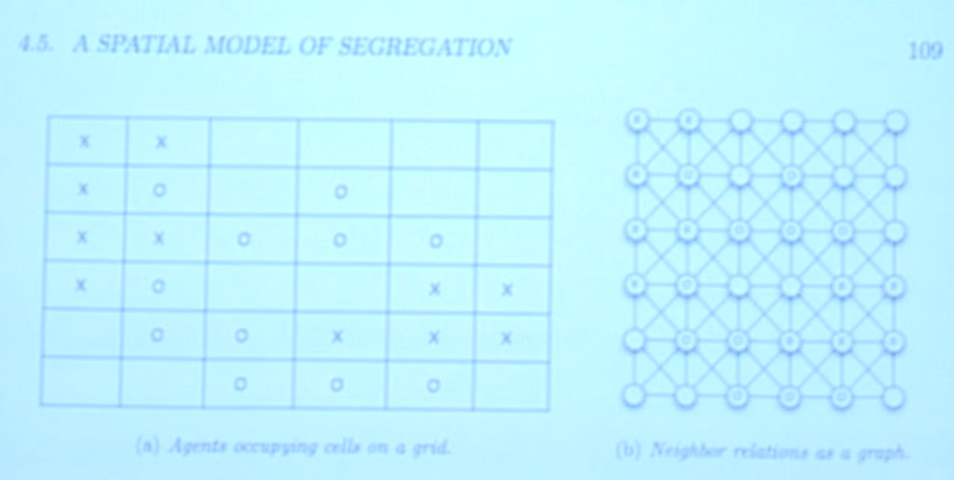
这个模型中有两种能动者,你要么是x,那么是o,x与o依据比如种族这类不可变的范畴而区分。这一模型预设的是,每个x和o都有特定数目的邻居与他们类似。这个模型假设当没有足够多相似的邻居在周边,这些能动者就会不开心、就会搬走。在每个阶段,当相似邻居小于3个时,不开心的能动者就会搬走。 这个模型带来的问题是,融合是及其难以达到的,照克莱因伯格和伊斯利所说,从一个随机的起点开始,一个能动者集体是非常难以找到融合图式的。 也许是吧,但是除非你抹除了美国的种族区隔历史,或根本不了解它,这个模型才可能是有效的。成为少数族群的欲望并非是天真的。如果你考察美国的种族隔离历史,这种依法的、强制的隔离,避免成为少数族群的欲望,当邻居“倾斜时(tipped,指的是谢林的种族隔离模型(Schelling’s tipping model))”就也想要搬走的欲望,解释了“白逃(white flight)”现象,而白逃是对70年代公民权运动的反应。 或者说它是对反种族隔离的反对。如果你用它来解释绅士化,就好像说穷人天生喜欢和穷人住在一起,所以就好像并非由于租金和税收增长而导致人们搬离,而是因为穷人天生喜欢和穷人住在一起。同质性更加令人不安的一点是它重新将恨定义为爱:爱就是爱同类,也就是逃离异类的欲望。 托马斯·谢林的原始出版物澄清了这些对机构的、经济的因素的抹除。 谢林1971年出版的种族隔离动态模型正是公民权运动的核心问题,而在此之前的一年发生了“废除种族隔离校车”事件。他的分析力图解释为何会有邻居“倾斜”的现象。他公然说种族隔离中的两个主要的过程可以被省略:他说他不考虑机构结构,即便它们很重要,他更不会考虑奴隶制和种族隔离制;同时身为一个经济学家,他不考虑经济因素,这令人诧异。我们看到他对抹除这些范畴的公然接受。而且他说“在这个模型的核心是不可动摇的、黑白分明的差异”。所以他假定了人群会彻底分成两个群体,每个人的身份都是永久的和可辨别的。 所以每个人都能观察出有多少其他范畴,每个人都能识别出有多少白人和黑人占据着他们的领地,任何人在任何时刻都有特定的位置。无论如何,这些假设都是很麻烦的,它们抹杀了种族的流动性,尤其是美国的种族身份的流动性。这个时期,在美国种族并不基于肉眼可见的差异的部分原因是“一滴血原则(one drop rule)”。 所以,在许多方面,种族隔离的兴起正是因为可见的差异并不足以确保种族识别。所以这个模型抹杀了数十年的批判性民族研究、性别、性倾向(sexuality)研究的学术历史。它抹杀了所有关于性别和种族的流动性、述行性问题。它抹杀了种族是社会性建构这一批判观点,而这一观点在纳粹大屠杀的恐惧之后曾被广泛地接受。我们看到一些关键文本讨论了、揭露了、记录了在启蒙时代兴起的现代种族观念,它是殖民和奴隶制的核心,它在人种改良学时代达到顶峰,在二战后开始有所转变,而在基因时代又再次出现。 所有这一切都被网络科学忽视了,它设定差异是不可改变的简单存在。那么,怎么办? 所以,第三部分叫做“拥抱不适,拥抱未来” 重点在于,我们当前所预见的未来并非不可避免。我们不必放任自己去扩大回声室。我们可以想象自我抵消式的预言模型,可以用它们来想象和争取不同的未来。虽然这需要比网络算法更多的东西,但我们不妨从网络算法开始。 我们来看看 乔安席森( Jo Ann Sison)和沃伦·萨克(Warren Sack)的挑战,他们搭建了民主搜索引擎,这个引擎会给用户提供最多样的结果,而非最流行的。 它挑战了所谓“流量计数”的假定,如果我们得到阅读量最小的文章而非最多的会如何?如果我们拥抱不同的条件、不同的初始设定会如何?我们还看到威﹒哈特(Vi Hart)对谢林的重新构想,她的数学模拟叫做“多边形的寓言”,令人赞叹。她的模型不基于与同类相处的欲望,而是破除隔离的欲望。它揭示的是初始条件的历史性的重要性,以及这些条件如何依赖重复的行为。
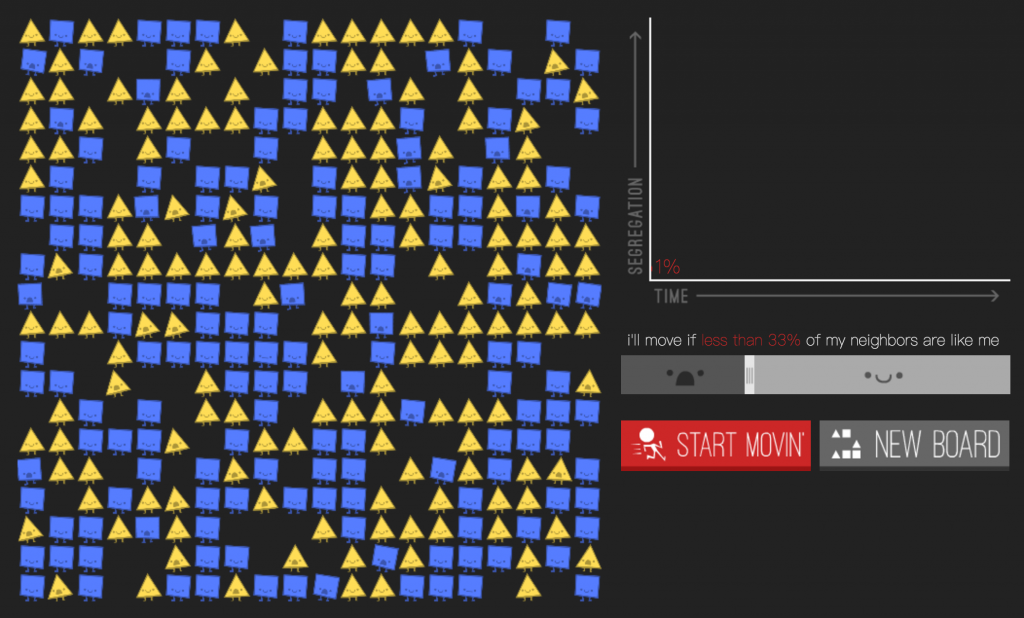
在来看看哈雷尔(Fox Harrell)的工作,他是计算媒体研究的先驱。他处理的问题是“人工智能是否能产生更加人性的互动”,他没有接受现下对种族、性别、阶级和性存在的区分,这些区分是不可变的,或者即便可变也只是简单范畴,只描述了节点。他所提出的是一种“高级身份表示”方法。这个计划要产主体认同的计算模型,主体认同现象与例如边缘化这种分类中的特殊形式有关,而它在工程架构中被忽略了。他已经完成了一个叫做“奇美拉:守护者”的系统。“守护者”是一类,而你是被边缘化的另一类,你得与守护者沟通才能前进。他称这个系统处理的是郭伏门(Ervin Goffman)的“污名(stigma)”概念,并且对抗“身份通行(identity passing)”的观念。 必须留意,仅仅强调身份的流动性或解构身份是不够的。现行的范畴是极其交错的。而哈雷尔的批判性工作处理了人工智能所包含的创造性。他问到:“人工智能是否能产生伟大文学作品,比如埃利森(Ralph Ellison)所写的《隐形人》,的影响力。”通过强大的想象力和文学创造力,人工智能是否能让读者经验到社会中的不可见的东西。它是否能引导创造一个更加正义的世界? 除了新型的人工智能,我们还需要新型的关联理论,要避免以平庸的、往复式的朋友关系概为前提,这很危险。如果关联意味的不是朋友关系,而是冲突或者无关将会如何?会有什么别样的集群形式和别样的搜索模型出现?当前的社交网络绝大多数都以往复双向式的关联来运作,如果我们提出一种单向的或多向的关联方式,会如何? 大家想想,朋友关系根本上、传统上来说是单向的。我喜欢你,但不见得你就总是喜欢我。如果我们认真考虑下单向的朋友关系,我们能如何搭建和思考别样的模式? 我们还需要酷儿化(queer)同质性,这个概念就其本性来就很酷儿。同质性难以处理异性恋问题,如果任何事物都能被按性别区分,女性、男性,你就不清楚会有什么样的配对可能。有趣的是,虽然麦弗逊( McPherson)在他的文章里指出柏拉图和亚里士多德主张同质性,但他在注脚里写到,柏拉图和亚里士多德在其他地方也说过,异性相吸。所以,认为柏拉图和亚里士多德预见了之后社会科学的发现,并不恰当。 阿美德用酷儿性(queerness)一词来表示在某些特定的规范下的不适。不适感正是受到身体与生活中长期存在的东西的影响。为了以不同的状态来适应这些规范,我们还需要拒绝舒适的观念。同质性总是出于舒适的观念,也就是说,处于类似的人群中,你会感到舒适。但转念一想,其实身处相似人群中是最不舒适的了,但我们往往忘记这一点。所以,与阿美德一道,我们可以想象新的初始设定,新的介入形式。 但最后,我们还需要重访历史,重新开启批判理论、批判民族志研究,我们需要更好的理论。在文化差异和认同问题如此要紧的时刻,人文领域和批判理论却抛弃了这些问题,实在令人惊讶。 所以,让我们创造新的联盟、新的剧本、新的理论,让我们充分地成为这场被苍白地称为“大数据”的戏剧中的重要角色吧。谢谢。 https://vimeo.com/206591086

