

The data spectrum: portable, usable & interoperable
Moving beyond just exportable data.
Portability
Many platforms and companies enable users to export their data. Twitter lets you export your followers, Substack lets you export your email subscribers, and Facebook lets you export a list of all your Facebook friends.
This data is considered portable: you can export it, archive it, back it up, print it out, frame it - the choice is yours.
Usability
However, the usability of this portable data varies. While you can export your Twitter followers' usernames, it doesn't grant you the ability to interact with them on other platforms or contact them outside Twitter. As such, Twitter data, though exportable, has limited usefulness.
Substack is a bit better: exporting a list of your subscriber's emails allows you to contact them directly.
The intersection of portability and usability can be visualized on a spectrum, with companies frequently moving along the scale as they evolve and achieve product-market fit (or, if they simply change their mind). Mailchimp allows users to export their subscriber emails but later changed their rules, locking out several cryptocurrency newsletters from accessing their subscriber list and abruptly shifting their position on the spectrum, moving from portable & usable to unportable.
The concept of data ownership is also relevant here. On Mailchimp, users technically did not own their email lists, as access to them could be revoked at any time. Truly owned data would always be both portable and usable, with no possibility for companies to alter the rules and restrict access.
Generally, companies lack incentives to make their data both portable and usable, as some degree of lock-in benefits them. For example, Twitter's network effects would be weakened if users could seamlessly migrate to Mastodon with a single click, taking their audience with them.
Interoperability
If a platform provides both portable & usable data, it's generally easy for users to migrate to competitors if they decide they dislike the platform. Though, why should leaving the platform be the user's only option if they dislike a particular feature or want a specific functionality not offered? Why should there not be some level of extensibility built in by default, letting developers customize to their liking and giving users more choice?
This is where interoperability comes into play. If data and functionality is interoperable, it can be extended and augmented and modified and built upon. Data isn't just portable anymore - it's composable.
Interoperability typically occurs using APIs: companies can expose core bits of their product through APIs, allowing other developers to interact with the underlying data or functionality.
Like portability and usability, interoperability exists on a spectrum, ranging from non-interoperable (no APIs) to partially interoperable (exposing a subset of functionality) to fully interoperable. Again, like portability and usability, companies can and often do move along this spectrum.
Substack data is currently portable - you can export your email subscribers - but they offer no APIs, and thus no ability to customize or extend the platform beyond what they offer.
Twitter, on the other hand, famously had a thriving developer ecosystem - they had nearly full interoperability, letting developers build whatever they wish. Users had an array of choice in how to interact with their followers - if they disliked the official Twitter client they were free to use an array of others. Retweets and other core primitives came as a result of developers - not Twitter! - building 3rd party apps. Then, some of these apps emerged as competitors, so Twitter crippled API access and shut them off.
Striving for full interoperability can align platform owners' incentives with those of their users, encouraging competition based on product quality rather than lock-in. Though, even with fully interoperable platforms, there's no guarantees that they'll continue to be fully interoperable in the future, as evident by Twitter.
The future
Users & developers alike should strive for portability, usability, and interoperability on the far end of the spectrum:
Fully portable. Users can export it and take it elsewhere if they wish.
Completely usable. Exporting the data actually allows the user to make use of it elsewhere.
Entirely interoperable. All data & features are exposed via APIs, letting developers extend & build upon functionality.
Of course, this is not sufficient - we also need strong guarantees that the level of portability, usability and interoperability won't change. To make these guarantees, the data needs to be owned by the user that created it or governed by some code that can't change. There can't be a centralized entity determining what data users are allowed to export, or what functionality is exposed via APIs (and how), since we've seen repeatedly that rules can be changed on a whim.
Building on top of sufficiently decentralized protocols and their associated primitives - not platforms - can help provide these guarantees. Networks like Ethereum, applications like Farcaster, and primitives like NFTs are making strides toward this future. For a developer building on top of Ethereum and using NFTs as a core primitive, there are protocol-level guarantees that rules won't abruptly change.
Wallets instead of emails for identity
Why open & permissionless systems can lead to better identity.
Most websites require your email address for creating an account. Email-based authentication allow the website to 1) contact you and 2) uniquely identify you.
Email does a good job at enabling contact - you can retrieve forgotten passwords just as easily as you can email your Grandmother - but it does a pretty poor job at identifying you. Given your email address, there's no understanding nor context about you, the user. Because of this, companies like Clearbit have built large businesses around enriching email addresses with data sourced from around the web, to make them more useful as identities.
OAuth
This lack of context & understanding is in contrast to other common mechanisms of identifying users, such as OAuth. Login with Google, Twitter or Facebook are a few examples of OAuth-based logins that go beyond just an identity - they let 3rd party developers tap into the closed data these companies have (for better or for worse).
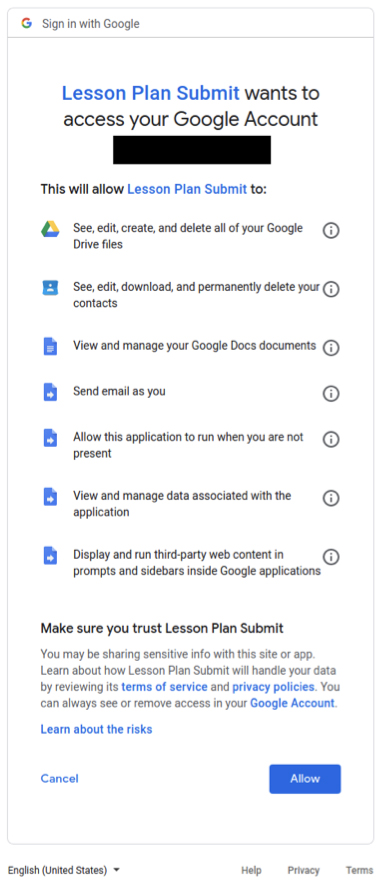
This helps identifiers moves beyond just an identifier, and toward becoming a user, with interests, friends, contacts, followers, profile pictures, genders, birthdates, and more.
This is powerful. As a developer, supporting “Login with [social platform]” lets you tap into this enriched data for numerous things:
Bootstrap network effects (eg prompting users to subscribe to all their Twitter followers immediately after registration)
Provide mechanisms of virality (eg automatically crosspost content they create to Facebook)
Provide better onboarding (eg pre-populating user accounts with avatars, interests and more)
There are several downsides to this method of OAuth based authentication, for both developers building atop these platforms and for users that authenticate with them:
Platforms can change the rules. Developers are constrained by what platforms allow. Google and Facebook are not credibly neutral open protocols - they're closed platforms with everchanging functionality. There have been many different instances in the past where platforms changed the rules and crippled developers building atop of them.
Developers get an incomplete picture. A user's audience is commonly split across multiple platforms. OAuth'ing with Facebook isn’t very beneficial to myself or the developer's app if 90% of my social graph exists on Twitter. It's unrealistic for developers to request or expect users to manually link with every single social platform to get a full picture.
User's can't exit with interoperability. If I decide I want to exit Twitter after the Elon Musk acquisition, it’s not possible to export my Twitter followers and use it elsewhere. Even worse - if Twitter decides to ban me, that’s it: there’s no way 3rd party developers building atop Twitter can make use of this data anymore.
Wallets
Using cryptowallets alongside crypto-enabled social protocols are an alternative that I believe will bridge the gap between an identity and a user and improve upon the aforementioned issues:
They are credibly neutral. Building atop sufficiently decentralized protocols, not platforms, guarantee that the underlying functionality won't change after I, as a developer, built a sustainable business.
It's easier to get a full picture of a user's social graph. As a developer, I can permissionlessly ingest the full social graphs of all web3 social platforms, just given a user's wallet address with no intervention from the user needed. If a user has never used Farcaster but is active on Lens, no problem -- I can still programmatically ingest both to get the complete picture.
Users can exit with interoperability. If users dislike (or are banned from) a specific client built atop a certain social graph, they can move to another client and continue interacting with the followerbase they've built at the protocol-level. Similarly, developers can continue making use of all the underlying data.
Though, crypto wallets are not without downsides. Adoption is currently low - everyone has an email but not everyone has a crypto wallet. Additionally, emails allow for easy message exchange but wallets currently do not (though many protocols are trying to fix this), so it's challenging to reach users strictly by their wallets. Lastly, privacy controls are non-existent: if I didn’t want to share a list of my on-chain followers with a certain platform, there’s no current method of preventing this (in contrast to the granular, user-controlled permissions that OAuth uses).
At Paragraph, we've built several integrations involving wallets-as-an-identity and it’s been a very positive experience. For example, when a user connects their wallet and signs in, we detect if they have a Faracaster account. If so, we permissionlessly pull in their avatar, name, & users they’re following, and bootstrap their Paragraph account by prompting them to subscribe to their followers. No gatekeeping, no OAuth, no action needed from the user - nothing beyond just a wallet address & credibly neutral social protocols.
Collect this post as an NFT:
Spending time deliberately
Thoughts on doing my best work.
Throughout any given day, my mood & state of mind fluctuates depending on many factors: quality of sleep, what I ate that day, how my personal relationships are going, how my company is doing, etc.
Because of this, I try to avoid a fixed schedule as much as possible. I view my day as fluid: I have a collection of different states of mind throughout the day, and I have a collection of work items that need to be done, so I try to match these up.
When I'm feeling creative, I write code or do frontend design. When I'm feeling insightful, I think about longer-term company strategy. When I'm feeling extroverted, I focus on user outreach and customer conversations. Mapping my states of mind to the appropriate deliverable lends itself to my best work. The opposite is also true - forcing tasks in an improper state of mind often produces worse results.
This is a simplified view - it certainly won't be possible in all jobs or on all days - but I'm fortunate enough right now that I'm able to abide by this as much as possible, given that an early-stage startup has time spent mainly between building and talking to users (and both of these have a spectrum of sub-tasks that tap into different states of mind). This is in contrast to my time spent at Google, where I often had days filled with back-to-back meetings.
Deliberately not working is also important. If I'm feeling awful and particularly unproductive, I prefer to make a conscious decision to step away and rest, in contrast to making little progress on something while beating myself up over the lack of productivity.