

Introduction
In the Toward Decentralized AI series, we’ve already covered Data Collection and Model Building, two of the better-known / more obvious stages of AI. However, especially in recent years, another area of improving AI performance has been popularized: retrieval augmented generation. If you’ve interacted with any generative model, you’re probably familiar with the lacking, outdated or ‘made up’ knowledge issues. This was especially a concern during the first launch of ChatGPT / GPT-3.5 and the other models around that time. Since then, we’ve started seeing more and more models with internet access, PDF/text uploads, or narrower knowledge focus. All of this ties back to retrieval augmentation, which, in its simplest form, means bringing knowledge in before generating something. As seen in the figure below, before the release of ChatGPT, research and advancement in RAG was relatively slow after its inception in 2017.

RAG combines the power of large-scale pre-trained language models (such as GPT-4) with the ability to retrieve relevant information from external knowledge sources (such as Wikipedia) on the fly. RAG models can dynamically query the knowledge sources during the generation process and use the retrieved information to enrich and guide the output. RAG models have shown impressive results in various tasks, such as answering questions, text summarization, dialogue generation, and more. Below, you can see how the WikiChat project implemented a RAG workflow and improved model performance.


However, RAG models also face several challenges and limitations, such as the cost and scalability of accessing and storing the knowledge sources, the availability and quality of the knowledge sources, especially for specific domains or niche topics, and the interoperability and compatibility of the knowledge sources with different AI applications. Many of these problems are still being investigated by various teams since both the technology and the applications are evolving rapidly.
In this article, we will explore how decentralization and blockchains can help address these challenges and enable a more efficient, robust, and collaborative way of creating and using knowledge-driven AI. As always, our approach will be strictly focused on AI’s problems that would make sense to be solved with decentralized methods rather than making up problems for decentralized tools to solve.
RAG Is Here To Stay
RAG models are important for several reasons.
They overcome the limitations of fine-tuning, which is the conventional method of adapting pre-trained language models to specific tasks or domains. Fine-tuning involves updating the parameters of the pre-trained model using a task-specific dataset, which can be costly, time-consuming, and prone to overfitting or catastrophic forgetting. Moreover, fine-tuning does not guarantee that the model will have access to the most up-to-date and accurate knowledge, as the knowledge embedded in the pre-trained model may be outdated or incomplete. RAG models, on the other hand, do not rely on fine-tuning but rather on retrieving the relevant knowledge from external sources at the inference time. This means that they can access the latest and most comprehensive knowledge available and adapt to different tasks or domains without re-training. RAG models can also handle out-of-distribution or rare cases that may not be covered by the pre-trained model or the task-specific dataset by querying the knowledge sources for additional information. Below is a comparison of fine-tuning and RAG performance from the {paper name} paper:

RAG enables a more natural and expressive way of generating content, as they can incorporate factual, contextual, and diverse information from the knowledge sources into the output. RAG models can also generate more coherent and consistent content, as they can keep track of the information that they have retrieved and used and avoid repetition or contradiction. They can generate more personalized and engaging content, as they can tailor the output to the user's preferences, interests, or needs by retrieving the relevant knowledge accordingly.
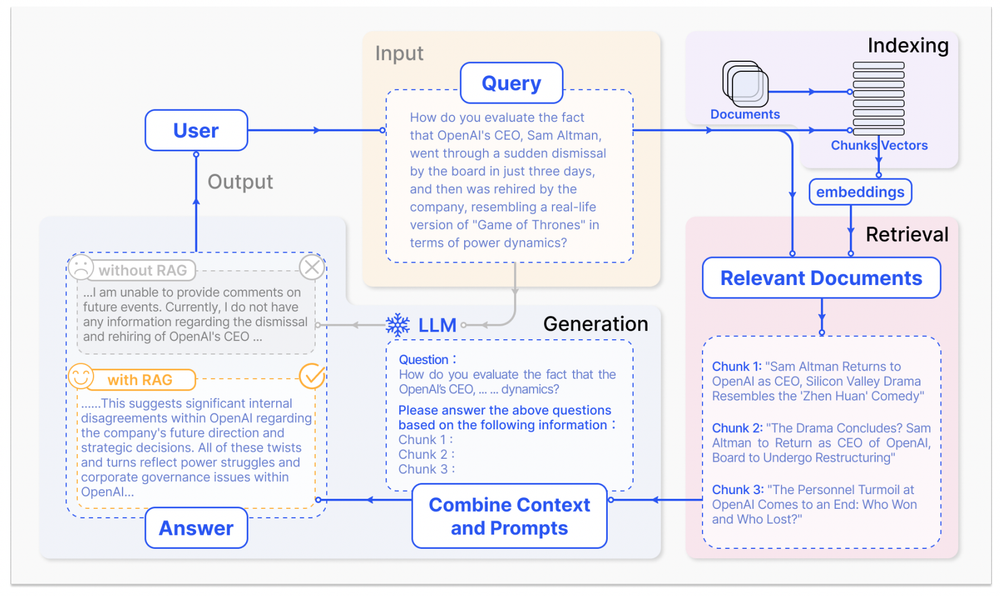
RAG models open up new possibilities and opportunities for AI applications, as they can leverage the vast and rich knowledge that exists in the world, both structured and unstructured, to perform complex and creative tasks that were previously difficult or impossible. For example, with RAG, one can generate summaries of long documents, synthesize information from multiple sources, answer open-ended or multi-hop questions, generate dialogues or stories with characters and plots, and more.
It’s Not All Figured Out
Despite the advantages and potential of RAG models, they also face several challenges and limitations that need to be addressed.
Doing RAG with publicly available knowledge is unnecessarily costly because everyone is finding knowledge, generating embeddings, and storing it on their own, repeating the same work done by others thousands of times. RAG models typically use a two-stage process to retrieve the relevant information from the knowledge sources: first, they use a dense retriever, which encodes both the query and the knowledge documents into vector embeddings, and then performs a nearest-neighbor search to find the most similar documents; second, they use a sparse retriever, which uses a keyword-based search to refine the results and extract the most relevant passages. However, this process requires a lot of computational resources and storage space, as the embeddings and the indices need to be generated and maintained for each knowledge source. Moreover, this process is redundant and inefficient, as different users or applications may use the same or similar knowledge sources and thus repeat the same work of finding, embedding, and storing the knowledge.
While general-purpose knowledge sources are easier to find, specific domains or niche topics are more challenging, as a single person or team cannot gather data on them easily. RAG models rely on the availability and quality of the knowledge sources, which may vary depending on the task or domain. For general-purpose tasks or domains, such as trivia or news, there may be abundant and reliable knowledge sources, such as Wikipedia or other databases, that can be easily accessed and used. However, for specific domains or niche topics, such as medicine, law, or art, there may be scarce or unreliable knowledge sources that may be difficult to access or use. For example, the knowledge sources may be proprietary, paywalled, outdated, incomplete, biased, or inaccurate. Moreover, a single person or team may not have the expertise, resources, or incentives to gather, curate, or update the knowledge sources for these domains or topics.
Other problems include the privacy, security, and trustworthiness of the knowledge sources, the alignment and compatibility of the knowledge sources with the user's goals and values, and the ethical and social implications of using the knowledge sources for AI applications. RAG models may also encounter other problems or risks related to the knowledge sources, such as:
The privacy and security of the knowledge sources, as they may contain sensitive or personal information that may be exposed or compromised by malicious actors or hackers or by the RAG models themselves if they are not designed or regulated properly.
The trustworthiness of the knowledge sources, as they may be subject to manipulation, misinformation, or disinformation by the creators, providers, or users of the knowledge sources or by the RAG models themselves if they are not verified or validated properly.
The alignment and compatibility of the knowledge sources with the user's goals and values, as they may reflect different or conflicting perspectives, opinions, or biases that may not match or respect the user's preferences, interests, or needs or may harm or offend the user or others if they are not filtered or customized properly.
The ethical and social implications of using the knowledge sources for AI applications, as they may have positive or negative impacts on the individuals, groups, or societies that are affected by the AI applications or by the RAG models themselves if they are not monitored or regulated properly.
Decentralization Can Help
Among the problems teams face while implementing retrieval augmented generation solutions, there are many problems that would be solved or at least find better solutions by putting some decentralized proccesses or methods in place. Here are some examples.
Global Shared Vector Database
A global public vector database that stores embeddings in a decentralized storage solution like Arweave can enable us to only create embeddings for a knowledge once and store it permanently, and everybody can access it. Decentralized storage solutions, such as Arweave, provide a way of storing data on a distributed network of nodes that is permanent, immutable, and accessible by anyone.

A global public vector database, built on top of such a solution, can store the embeddings and the indices of the knowledge sources that are generated by the RAG models or by other users or applications and make them available for reuse by anyone. This can reduce the cost and redundancy of finding, embedding, and storing the knowledge and increase the efficiency and scalability of the retrieval process. Moreover, this can also ensure the privacy and security of the knowledge sources, as they are encrypted and distributed across the network, and the trustworthiness of the knowledge sources, as they are verified and validated by the network.
Dria
Dria can be described as a multi-region, decentralized, public vector database. It functions as a collective memory hub for AI. It allows anyone to upload their unstructured or structured data, transforming it into easily queryable decentralized vector databases. This facilitates permissionless access to AI knowledge. All data is turned into vector embeddings and stored in a decentralized way, making it globally accessible to users and developers for various use cases.

Dria is designed to store information in formats understandable by both humans and AI, ensuring universal accessibility. It supports different data formats and is fully decentralized. Each index in Dria is a smart contract, enabling permissionless access to knowledge without relying on centralized services. It also features an API for knowledge retrieval, implementing search capabilities with natural language queries.
Dria simplifies knowledge contribution and enhances access to AI knowledge. Users can effortlessly retrieve information from the Dria Platform by using the search bar. In addition to the platform, Dria provides native clients to facilitate the development of Retrieval Augmented Generation (RAG) applications. However, the most valuable aspect of Dria is its commitment to open and permissionless access to all knowledge within its platform. Developers can access any knowledge and retrieve information on their local devices using open-source Docker images released by the Dria team.
Dria has ~2000 datasets from various domains, including full articles of English Wikipedia and Wikipedia Simple. This ensures the Dria’s knowledge hub is useful for a large variety of tasks and use cases.
Here’s a diagram showing how Dria saves time and money throughout various steps of the RAG process:

Crowdsourcing Knowledge
A public access decentralized vector database can enable efficient crowdsourcing mechanisms that make it easier to feed niche knowledge to AI applications. A decentralized vector database can also enable efficient crowdsourcing mechanisms that can incentivize and facilitate the creation and curation of knowledge sources, especially for specific domains or niche topics. For example, users or applications that need or use the knowledge sources can pay or reward the creators or providers of the knowledge sources using cryptocurrencies or tokens that are issued and managed by the decentralized vector database. Alternatively, users or applications that have or produce the knowledge sources can share or sell them to other users or applications using marketplaces or exchanges that are built and operated by the decentralized vector database. This can increase the availability and quality of knowledge sources and foster a more collaborative and diverse ecosystem of knowledge-driven AI.
Finding The Right Knowledge
With crowdsourcing a large number of datasets, it quickly becomes much harder to find the right knowledge. To ensure the knowledge feeded to the AI model for RAG is in fact improving its performance, there should be a mechanism in place that finds and chooses the right knowledge based on some pre-determined criteria. This mechanism acts almost like a librarian bringing the relevant books based on one’s study topic, checking a set of high-performing datasets to see if they are relevant to the AI’s tasks. In a decentralized RAG system, such a librarian can find the necessary smart contract and retrieve the knowledge quickly, providing easy access to significant performance upgrades.
Knowledge Assets
Knowledge assets (KWAs) are a novel form of tokenized real-world assets (RWAs) that represent units of knowledge on the blockchain. Unlike other RWAs, such as art or real estate, knowledge is intangible, dynamic, and subjective. Therefore, KWAs require a different approach to valuation, verification, and exchange. KWAs can be created by anyone who has some knowledge or expertise in a certain domain and can be verified by a network of peers or experts. KWAs can also be rated, ranked, and categorized according to their quality, relevance, and usefulness.
KWAs can be used for improving retrieval augmented generation (RAG) applications, which are natural language processing (NLP) systems that leverage large language models (LLMs) and external knowledge sources to generate text. RAG applications can benefit from KWAs in several ways. First, KWAs can provide a rich and diverse pool of knowledge for RAG applications to retrieve and augment their LLMs, improving their accuracy and performance. They can enable RAG applications to access and use proprietary, private, or dynamic data that are not available in public knowledge bases, enhancing their customization and personalization. KWAs can also incentivize RAG applications to produce high-quality and valuable text, as they can reward the creators and users of KWAs with tokens.
KWAs can facilitate the development and deployment of RAG applications, as they can reduce the cost and complexity of retraining LLMs for specific domains or tasks. Instead of retraining LLMs with large and static datasets, RAG applications can use KWAs as dynamic and modular knowledge units that can be easily updated, combined, and exchanged. KWAs can also enable RAG applications to explain their reasoning and sources, as they can provide metadata and provenance information for each knowledge unit. This can increase the transparency and trustworthiness of RAG applications, as well as their compliance with ethical and legal standards.
AI-Knowledge Blockchain
There can be an AI-knowledge-focused app chain/L2 where different apps can generate knowledge assets (share query revenue, stake for trust, tokenize any knowledge, etc.) and make them tradable globally. This increases the interoperability of RAG-dependent applications and makes it easier to bootstrap apps. A decentralized vector database can also enable an AI-knowledge blockchain, where different apps can generate knowledge assets that are based on the knowledge sources and offer them to the market. These knowledge assets can be exchanged or traded on the platform, providing a way for creators to monetize their knowledge and for users to access a wide variety of specialized knowledge. The AI-knowledge-focused blockchain could also provide a framework for establishing trust and verifying the quality of the knowledge assets.
Conclusion
While RAG has shown impressive results in various tasks even with its current state, there are some areas where decentralized infrastructures, applications, and assets can help RAG become more efficient and effective through higher quality knowledge and lower costs.
In the next article of this Toward Decentralized AI series, we will focus on how decentralization can play a key role in AI safety.
References
This article was originally posted on the FirstBatch blog. It was reviewed by Batuhan and Kerim, edited by İlkyaz.

when i went to see the Mona Lisa as a kid i was grumpy and then said “you made me walk all the way for this? she’s not even that pretty” & I could say the same about crypto x ai rn feels like a dud unless someone brings up a direct use case (talking about tech not tokens)
Well my mom scold me for choosing a BAYC than a $100 cash.
Very true. For a long time I wanted things to speak to me without realizing it’s me who need to learn their language Just like I can’t read a good story written in a foreign language, I can’t appreciate art, architecture without learning more about the lore Same with tech
that's a fair take based on what we've seen so far, but there are strong use cases too. Some basic ideas in the article below, will write a more detailed one soon. (I can also send you a whitepaper on what's cooking) https://paragraph.xyz/@lab/toward-decentralized-ai-part-3-retrieval-augmented-generation
this whole Farcaster/drakula experience is a use case it's just decentralized/public databases and money
couldn’t agree more— also lots of confusing lingo (like your other post), hopefully the superchain comes up with a fix. 1000 $DEGEN
Using crypto to access GPUs on consumer devices seems like a logical crypto-native use case for which I would expect demand, at least on the inference side of things. Render and IO net are doing this. Crypto to bring provenance to data also makes sense to me. Can’t make sense of the rest
disagree when i finally understood Bittensor's incentive mechanism, i think it will be huge.