
In the previous post, we surveyed the landscape of existing science communication infrastructure and how it motivates Sensemaking Networks, an integration of semantic nanopublishing and AI-augmented social media networks. Nanopublishing brings best practices of open scholarly infrastructure and leverages semantics to radically enhance interoperability and information flow. Social media apps bring usability, rapid feedback loops, and the power of algorithmic reach.
In this post, we'll begin discussing actual implementation plans.
🚧This project has a lot of moving parts, so we expect ongoing iteration to improve the plan! 🔄
We're currently planning two mutually supporting efforts: (1) recovering existing nanopublications from social media, and (2) building a social app for semantic nanopublishing based on open social networking protocols like ActivityPub and AT Protocol (the protocols underlying Mastodon and Bluesky).
As discussed in the last post, researchers are already nanopublishing on social media, but because the infrastructure doesn’t actually support it yet, valuable scientific knowledge is being lost through data enclosure and fragmentation. Fortunately, powerful NLP (Natural Language Processing, a.k.a large language models and friends) tools can help us recover some of this knowledge and make it available on the open scientific record.
This effort will focus on detecting mentions of research in social media posts, linking them back to their authors and inferring their semantics where possible. Recovering semantics from natural language is called parsing in NLP.
For example, consider this tweet on social media:

We evaluated GPT-4 in a public online Turing Test. The best-performing GPT-4 prompt passed in 41% of games, outperforming baselines set by ELIZA (27%) and GPT-3.5 (14%), but falling short of...
Melanie Mitchell, an AI researcher, mentioned an arXiv pre-print “Does GPT-4 Pass the Turing Test?”. Extracting this mention is already useful, and services like Altmetric collect these mentions as a simple proxy for attention over research. But we can go further with NLP, and try to parse this post into a nanopublication template which contains richer semantics. In this case, there is a template for “Commenting on or evaluating a paper”. For demonstration purposes, I played the role of an NLP model and manually parsed the tweet into that template:

This new form with semantics is much more useful than the raw natural language tweet!
Semantics are machine readable, enabling downstream apps to do all kinds of useful operations. For just one example, consider the landing page for papers, like you can find on arXiv or bioRxiv as shown below:
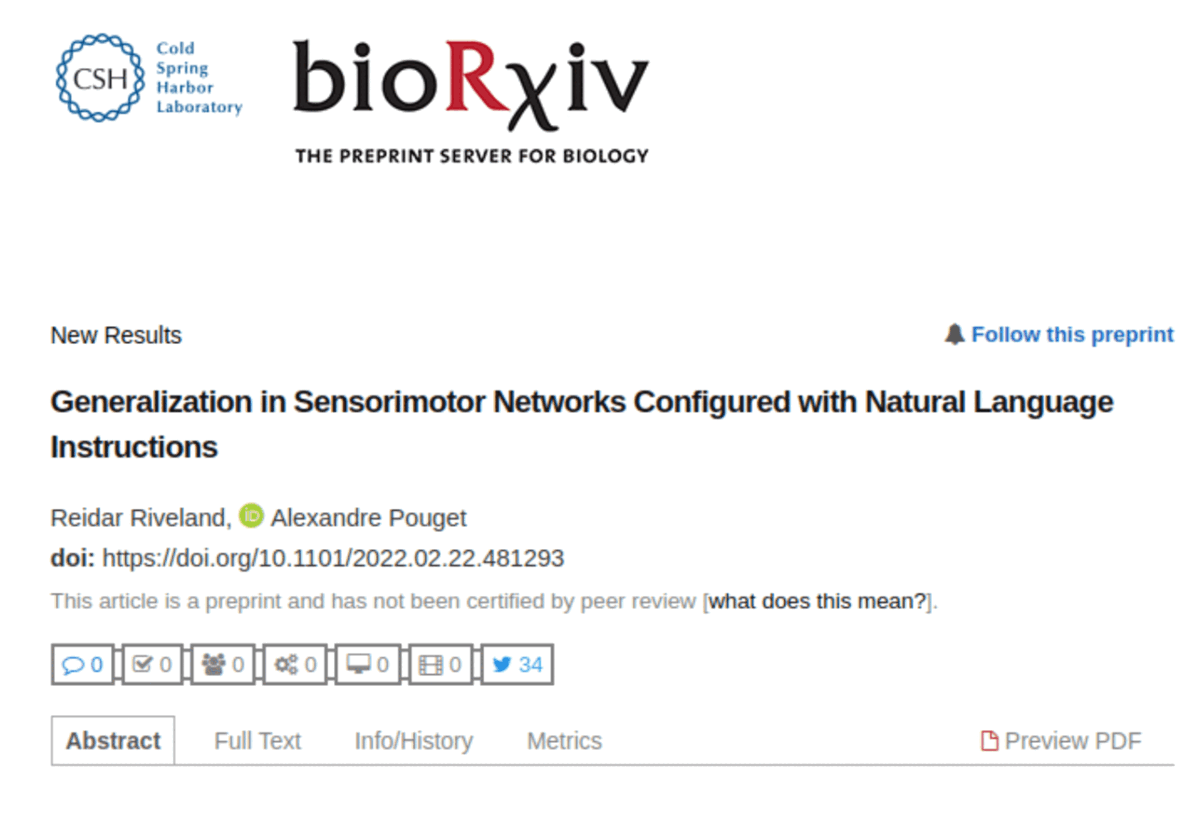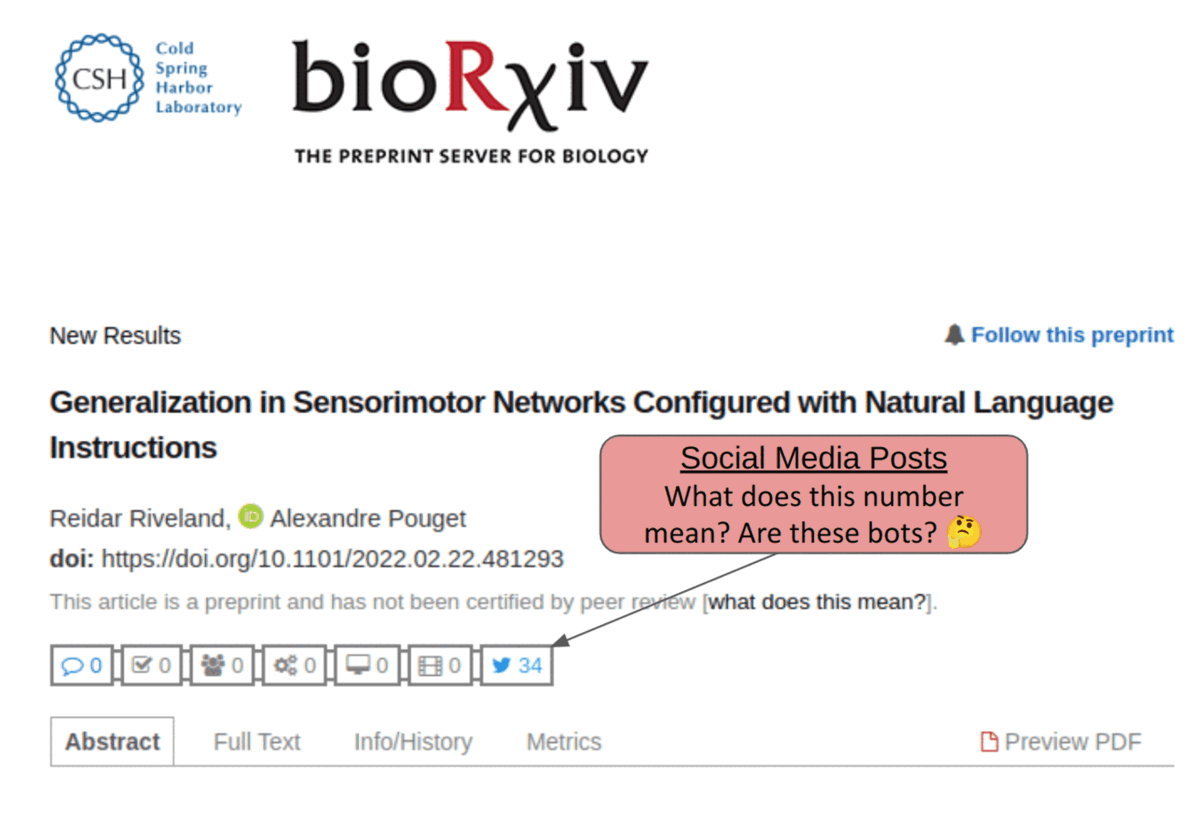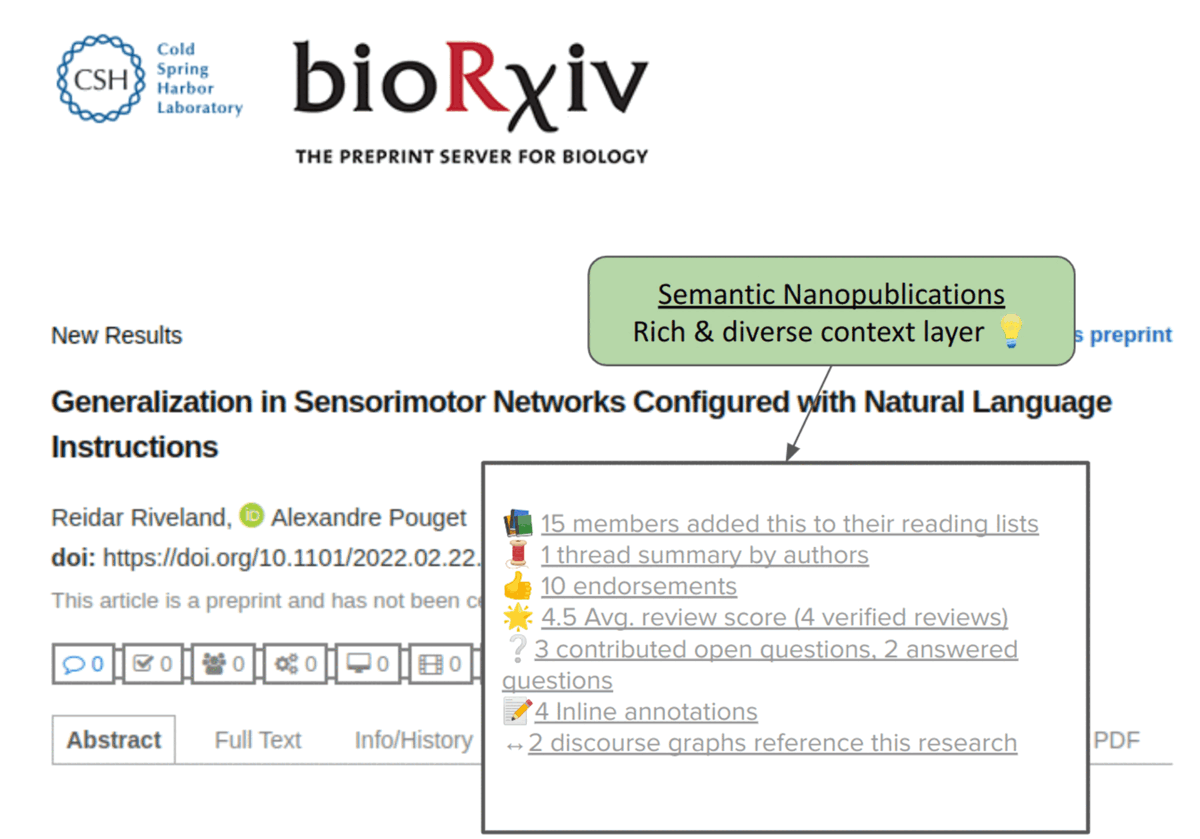
These landing pages often track social media mentions of research (using services like Altmetric as mentioned above), but since those posts lack semantics, all that can be done is a simple count display tracking how many times the research was mentioned. As a result, much information is lost, limiting the value of such signals. Now imagine we had semantics. We could display how each mention referred to the research in question, providing a much richer context for those who want to explore the discussion about a particular paper (please excuse the crude mockup, this is just for demonstration purposes!). This is just one example of many apps enabled by semantic publishing: more on that in future posts!
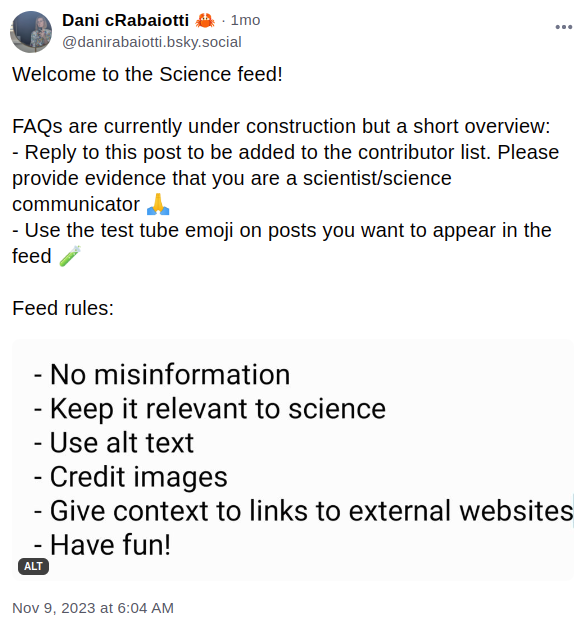
Another important contrast with services like Altmetric is that of consent. These services collect researchers' data without their consent or knowledge. Some may question whether consent matters in this case, given that tracking is only being conducted around scientific discourse, and social media data is public anyway. However, our mission is different, which is why we think consent matters: where existing services are focused on passive tracking of researchers' behavior (that gets creepy fast), Sensemaking Networks are aimed at developing active, participatory and ultimately more useful discourse around research (more here on the transition from "users to [sense]makers"). In this new model, data sharing and collection are intentional practices employed by communities and for communities to support their collective sensemaking efforts. Accordingly, we plan to experiment with different methods enabling researchers to have more control over the data they contribute. An early interesting example we've been inspired by is the Science Feed on Bluesky. As shown below, researchers can register themselves to the feed which then aggregates all of their posts marked with a 🧪 emoji:
However, even if we address consent issues, converting social media posts to nanopublications using NLP is not a cure-all. While it can be extremely useful for bootstrapping the network, it is still only a partial solution: for one, AI tools are still far from perfect, despite truly impressive recent progress. In addition, many platforms have closed off their APIs completely or are making it increasingly costly to extract data. As observed by Barend Mons, one of the leaders of FAIR data and nanopublications, “Text mining? ...Why bury it first and then mine it again?”
That’s why we’re also planning to build a nanopublishing social app for researchers to use!
There are a number of reasons why using an app for semantic publishing often makes more sense than writing unstructured natural language posts on social media, and hoping some AI system in the future will be able to make sense of it:
Semantic publishing produces machine-actionable data. Unlike text mining, semantic publishing can instantly and directly power downstream applications. For example, sharing a review on Goodreads is a form of semantic publishing: the structured data is the review, which the app (Goodreads) can then process in useful ways (computing aggregate ratings for books, showing your friends updates, etc). However, in this example, the published data is also enclosed by Goodreads, meaning that only Goodreads can directly benefit from your data.
Preserving data accessibility. Sensemaking Networks are designed to be resistant to platform enclosure, by building on top of open and decentralized social networking protocols like ATProto and ActivityPub. In an open ecosystem, the same data could play a role in multiple apps in parallel. For example, your social graph from Mastodon could also be used to filter reviews on an open & decentralized "Science Goodreads," instead of the situation today where each new platform forces you to create and maintain a new social graph. This transformative vision of radical interoperability and decoupling of apps from data is certainly not new, and indeed was the dream of early "Web 1.0" Semantic Web pioneers like Tim Berners-Lee. See below for some more thoughts on why the time might be right to revisit these exciting ideas.
Preserving human authority. Finally, the very idea of AI automating the recovery of semantics from natural language without human supervision stands in tension to the principle of source authoritativeness in semantic publishing:
"Semantic representations can only be considered authentic if they originate from an agent that is authoritative in the given situation. In the case of the publication of a scientific result, the only authoritative source are the researchers (who are called authors in this context). Semantic representations of scientific results are only authentic if they are provided by the researchers themselves, and this relation can be made explicit with a precise provenance representation." -- Kuhn & Dumontier (2017). Genuine semantic publishing
This argument is especially relevant in an age of rampant AI-generated content. Tracking the provenance of information and being able to discern what was generated by humans vs AI agents will be increasingly important. In many cases, AI might assist researchers in generating content, but humans must remain the ultimate arbiters: "any attribution of authorship carries with it accountability for the work, and AI tools cannot take such responsibility."
One simple option is: just like Mastodon, Bluesky, or equivalent apps, but with the key difference that instead of publishing just posts, users can nanopublish, meaning that they can select a template best expressing the semantics of their message.

Besides appearing in other people's feeds, radical interoperability means these nanopublications can also easily flow into other apps and services. Continuing the example of the bioRxiv landing page from Section 1 above, a researcher's nanopublished assessment of some paper could directly appear in context on the landing page of that paper, in addition to appearing in social media feeds. Similarly, inline annotations (like those made using hypothes.is) could "live" simultaneously on social media and as a layer over web content:
Semantic publishing needs to be as easy and natural as posting on existing apps, and great UX + AI assistants will be key to making that possible. For example, users can start typing their post in natural language and an interactive AI assistant can suggest suitable templates. More broadly, one of the reasons that early versions of the Semantic Web didn't pan out as expected was that they introduced additional friction and technical complexity that people were not prepared to handle. We're excited by the promise of revisiting semantic publishing with the benefit of years of progress in AI, interface design and distributed computing technologies!
Building great infrastructure is a huge undertaking, and a fuller realization of Sensemaking Networks is ultimately beyond the scope of a one year residency. Also, our goal is not to build yet another social media platform! Rather, evolving, interoperable and collaborative ecosystems are both the means and ends of the project. Therefore, we're building partnerships with mission-aligned organizations to create this new ecosystem, together. Shout-outs to some awesome groups we've already started working with (hopefully lots more to come soon!):
Knowledge Pixels who are developing developing the Nanopublications project
And of course, we're very excited to continue building our collaboration within Astera and its network.
As usual, thoughts and comments are very welcome - feel free to reach out at ronen@astera.org
That's all for now! Hopefully next time we'll have some actual screens or prototypes for you
Happy 2024, make merry and make sense! 🔄🍾

Subscribe to Cosmik: Collective Sensemaking Networks
Over 100 subscribers
Re-imagining how we make sense of science


 1,602
1,602
