



Sensemaking Networks Part 3: building partnerships and prototypes
Semantic cross-posters for re-integrating science social media
Ronen Tamari, Shahar Refael Oriel and Pepo
5 min read·
Hello again fellow science sensemakers!
We just got back from DeSci Denver and have a lot to unpack, both from the conference as well as from the last couple of months. To TLDR - interviews with researchers inspired us to develop a semantic cross-poster that can nanopublish alongside posting to social media. We built our first prototype and presented it at DeSci Denver. We also created an LLM-augmented interface for querying the nanopublications network, with an eye towards enabling next generation natural language knowledge interfaces. “Sensebot, summarize the debate around this paper, and show me the positions of the researchers in my network” (ok, we still don’t support that query yet, but we’re working on it :) )

Since January we’ve been meeting researchers from all walks of science to learn how they use social media for their research, and how they’d like to improve it (we prefer to call them (sense)makers, not users!)
These sessions helped us appreciate the great diversity of ways in which researchers acquire and share information. For example, some avoid social media in favor of personal knowledge tools like Roam Research, while others use their social media account itself as a public knowledge repository of sorts. Some researchers use cross-posters as a way to deal with social media fragmentation; cross-posters publish their content simultaneously to multiple platforms.
We also learned that open social media does not necessarily mean an invitation to scrape data: in some science Mastodon communities for example, bots are actively discouraged, even for research purposes.
These learnings informed our design process and led us to update our project plan. Rather than building another social media crawler, we decided to start with a semantic cross-poster; a cross-poster that enables authors to easily publish to the Nanopublications network, adding rich machine-readable semantics to their posts, beyond just text and media. A semantic cross-poster is relatively simple technically, making it an attractive starting point. Furthermore, it aligns with the human-centered design principles guiding our project:
Cross-posters preserve consent: people are subjects that author their posts rather than data point objects to be scraped unknowingly, as in services like Altmetric.
Cross-posters “meet people where they are” by integrating with the tools and practices they already use. Beyond social media integrations, cross-posters can also interface with personal knowledge systems.
Semantic cross-posters enhance people’s agency: semantics increase posts’ discoverability by making them FAIR (Findable, Accessible, Interoperable, and Reusable) and provides authors more control over how the algorithm “sees” them. Instead of outsourcing decisions to opaque AI algorithms far off “in the cloud”, authors are participants in decision-making loops and control how their data is intended to be read by machines. FAIR and semantic data also enhance collective intelligence by connecting posts in a distributed knowledge graph that can power customizable feeds and recommendation systems.
Cross-posters save researchers time and energy by enabling them the option of automating potentially tedious tasks like adding semantics, making data FAIR, and manually posting to different platforms. A planned feature we’re particularly excited by is auto-posting, enabling authors to define a single input source that will automatically be monitored and cross-posted from whenever new content is published on it. For example, authors will be able to automatically cross-post from their Twitter account whenever a new post about research is detected (with the option of a quick manual vetting to correct errors).
Semantic auto-cross-posting effectively enables a kind of “self-sovereign scraping”. Traditional scraping happens in the background with no user involvement. While the fact that it requires no user attention may be seen as convenient, it also seriously limits their control. There is no easy way to opt out of scraping, and also no way to influence what data is being collected about you. In contrast, our semantic cross-poster will enable people to benefit both from convenience and also control over what data they share, and how.
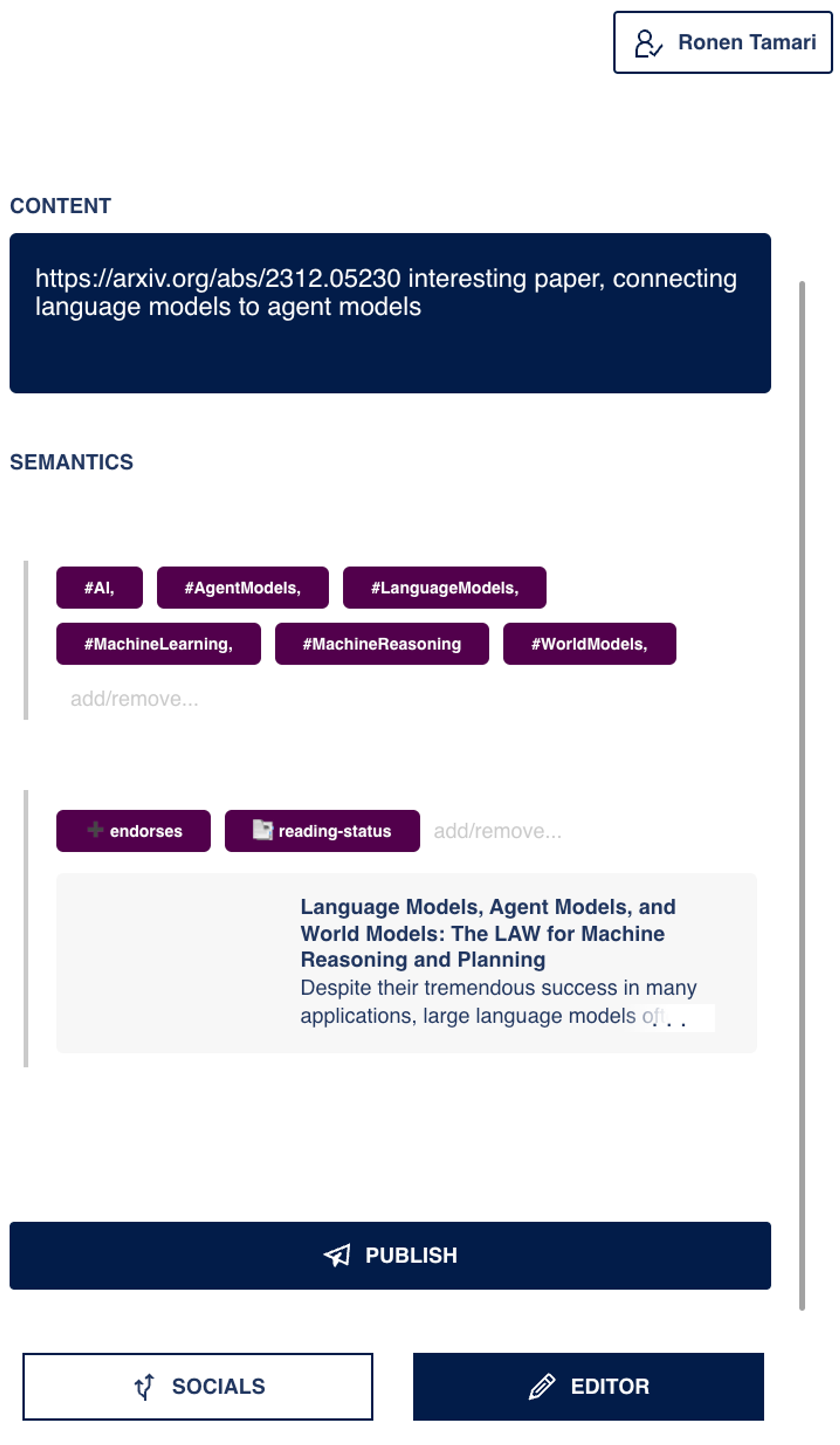
In February we built our first prototype, which supports cross-posting to Twitter and the Nanopublications network. Semantics are extracted using a Langchain LLM pipeline (we experimented with the Mistral open source model and GPT-4). We are also experimenting with LLM pipelines for automated keyword extraction. For nanopublishing we use the nanopub-rs library(https://github.com/vemonet/nanopub-rs), and we streamlined the private key management using web3 wallet services. The screenshot to the right demonstrates an example, and you can check out this video for a quick walkthrough (see the resulting nanopub here). We’ll share more technical details as we stabilize the app.
Representing Semantic Web concepts requires an ontology, which describes the concepts and possible relations between them. Our ontology is called Common SenseMaking Ontology (CoSMO). CoSMO is designed to represent the diverse ways in which researchers relate to research on social media. CoSMO is based on the classic Citation Typing Ontology (CiTO) which characterizes citation relations in scholarly works. For example, CiTO includes concepts like agreesWith, repliesTo, and citesAsRecommendedReading. Where CiTO is focused on more traditional scholarly citations, CoSMO is an updated adaption for sensemaking on digital social networks, including concepts from CiTO but also support for other kinds of media like podcasts and videos, as well as mentions of events or job opportunities. The current version is just a start, and we expect to evolve CoSMO as we deploy the cross-poster in actual communities. In the future, we’d also like to enable communities to easily extend and adapt ontologies to their specific needs.
As discussed in previous posts, nanopubs implement the FAIR standard. A key to nanopubs’ Findability is the SPARQL query language, which provides a powerful tool for querying the nanopublications network. Queries can power diverse range of applications such as configurable feeds, recommenders and question answering systems. Query languages such as SPARQL have existed for years but remain underutilized because they're technically demanding. Like with semantic publishing, we're enthusiastic about the potential of using large language models (LLMs) to simplify access and create powerful yet user-friendly, natural language-driven interfaces.
From some preliminary experiments we can already see great potential. For now, we’ve tried simple queries like “show me all critiques of this paper” and “show me all paper recommendations from this list of researchers”.
We’re excited by the potential of more complex queries powering next-generation knowledge interfaces. Interfaces that used to be firmly in the domain of sci-fi are now an imminent possibility:
“summarize the debate around this paper, and show me the positions of the researchers in my network”
“show me the people in this conference who have read any of my papers and enjoyed them”
“keep me notified on all job offers in biodiversity research in institutions which are affiliated with any researchers in my network”
Interestingly, these kinds of queries are simply not possible even with the best LLMs today, since they rely on structured semantic knowledge graphs in addition to powerful NLP capabilities. “chat with paper” bots are cool, but we think that combining LLMs with nanopubs unlocks a whole new class of interfaces grounded by semantics and attributable to actual human comments. Such systems will be much less prone to hallucination, and will help connect between human researchers rather than disintermediating them through unreliable and opaque models.

Our whole team met in DeSci Denver at the end of February to present and demo Sensemaking Networks (slides). It was an exhilarating week, and our heads are still spinning from all of the new connections and ideas that emerged from the conference!

We were especially energized by discussions around coordinated efforts to bring DeSci and open science projects more into the mainstream. Imagine a movement of scientists opting in to collectively FAIRify their social media communications around science! Given the existing fragmentation across platforms, the situation can seem pretty hopeless at times, but we were excited to learn that we share these dreams with many others. John Lennon once said: “A dream you dream together is reality.” Shared dreams + great shared open science infrastructure=✨
If you’re excited by these dreams as well, we’d love to hear from you! Connect with us here if you’re interested in joining our beta when it’s ready, or any other collaboration!